23.1. Algunos aspectos internos de INN
El núcleo de INN es el demonio innd. La tarea de innd es manejar todos los artículos entrantes, los almacena y se los pasa a cualquier proveedor de noticias que los requiera. innd se activa cuando se carga el núcleo del sistema y queda trabajando de forma continua en segundo plano. Corriendo como demonio se incrementa el rendimiento ya que solamente cuando se inicia se leerán los archivos de estado. Dependiendo del volumen del proveedor de noticias, algunos archivos como por ejemplo history (que contiene una lista de todos los artículos procesados recientemente) puede estar en el rango que va desde unos pocos megabytes hasta varias decenas.
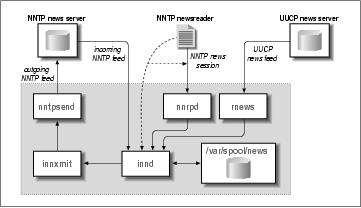
Otra característica importante de INN es que solamente hay una copia de innd ejecutándose todo el tiempo. Esto es muy beneficioso a nivel de rendimiento, ya que el demonio puede procesar todos los artículos sin tener que preocuparse por el sincronismo de sus estados internos con otras copias de innd que se encuentran revolviendo la cola del servidor al mismo tiempo. Sin embargo, esta opción afecta el diseńo global del sistema de noticias. Debido a esto, es importante que las noticias entrantes sean procesadas lo más rápidamente, es inaceptable que el servidor esté amarrado a tareas mundanas tales como darle acceso a un cliente de noticias vía NNTP o descomprimir paquetes que arriban vía UUCP. En consecuencia, este tipo de tareas deben ser separadas del servidor principal e implementadas por otros programas. Figura 23-1 intenta ilustrar las relaciones entre innd, las otras tareas locales, lo servidores y clientes de noticias remotos.
Hoy en día, NNTP es el medio de transporte más común en cuanto a noticias se refiere, y es el único que innd soporta directamente. Esto significa que innd continuamente esta escuchando el puerto 119 (TCP) y acepta las conexiones que utilizan el protocolo “ihave”.
Los artículos que arriban por otro tipo de transporte que no sea NNTP son soportados de forma indirecta haciendo que otros procesos acepten los artículos y se los reenvíen a innd vía NNTP. Los paquetes que provienen de un enlace UUCP, por ejemplo, son tradicionalmente manejados por el programa rnews. Este programa descomprime los paquetes si es necesario, y separa cada uno de los artículos; echo esto, se los ofrece a innd uno por uno.
Los clientes de noticias, pueden entregar un artículo escrito por un usuario. Como el manejo de estos clientes merece especial atención, volveremos a este tema un poco mas tarde.
Cuando recibe un artículo, innd primero mira el identificador el mensaje (message ID) en el archivo history. Los artículos y ocurrencias duplicados, son descartados y opcionalmente registrados en algún archivo de eventos (log). Lo mismo sucede con artículos muy viejos o por ausencia de algún campo requerido, por ejemplo Subject:.[1] Si innd encuentra que el artículo está en orden, busca en el campo Newsgroups: para saber a que grupos de noticias fue remitido. Si alguno o todos estos grupos es encontrado en el archivo active, el artículo es archivado en el disco. De otra manera, es archivado en un grupo especial llamado junk (Basura).
Los artículos individuales son guardados en /var/spool/news, también llamado cola de noticias (news spool). Cada grupo de noticias tiene su propio directorio, en el cual cada artículo es guardado por separado en un archivo. Los nombres de estos archivos son números consecutivos, por ejemplo, un artículo publicado en comp.risks será guardado como comp/risks/217. Al momento de guardarlo, innd busca el directorio donde debería ubicarse, si no se encuentra, lo crea automáticamente.
Aparte de guardar los artículos localmente, Ud. puede reenviarlos a otros servidores. Esto es gobernado por el archivo newsfeeds donde están enlistados todos los servidores de menor jerarquía a los cuales se les deben pasar los artículos.
De la misma forma que innd maneja el proceso de entrada de los mensajes, maneja en una sola interfase, los que salen. El mismo puede manejar todo el transporte saliente. Sin embargo, necesita de varios motores que envíen los artículos a los demás servidores. Todos los recursos para el envío es apodado en forma colectiva canales (channels). Dependiendo de su propósito, un canal puede tener diferentes atributos que determinen exactamente que información debe pasarle innd.
Para un suministro NNTP saliente, por ejemplo, innd podría bifurcar el suministro hacia el programa innxmit al comienzo, y por cada artículo pasarle el identificador, el tamańo, y el nombre del archivo hacia su entrada estándar, por otra parte, si se usa UUCP como suministro, innd puede escribir el tamańo del artículo y su nombre en un registro especial, el cuál es la cabecera de un proceso diferente a intervalos regulares en orden de crear los archivos por lotes y hacer la cola para el subsistema UUCP.
Además de estos dos ejemplos, existen otros tipos de canales que no son estrictamente para suministros de salida. Estos son usados, por ejemplo, cuando se desea archivar ciertos grupos de noticias, o cuando se quiere generar información general. Esta información general es creada con la intención de ayudar a los lectores de noticias a seguir el hilo de un tema de manera más eficaz. Los viejos lectores de noticias tienen que buscar en todos los artículos de forma separada para obtener la información contenida en las cabeceras utilizada para seguir el hilo de los mensajes. Esto impone una pesada carga al servidor, especialmente cuando se usa NNTP; adicionalmente, es muy lento. [2] El mecanismo de información general alivia este problema pregrabando las cabeceras que son relevantes en un archivo separado (llamado .overview) por cada grupo de noticias. Esta información puede ser recogida por los lectores de noticias leyendo directamente desde el directorio donde se encuentra la cola de los mensajes, o usando el comando XOVER estando conectado vía NNTP. INN tiene al demonio innd para suministrar todos los mensajes usando el comando overchan el cual es adosado al demonio a través del canal. Luego veremos este método cuando se discutan las configuraciones de los suministros de noticias.