4. Acentos y otros caracteres especiales
Algunos caracteres distintos de los habituales en los lenguajes anglosajones son considerados en el mundo de la informática como caracteres especiales. Dentro de estos se incluyen las letras acentuadas ni la letra eńe.
En los últimos ańos se ha avanzado mucho en conseguir que cualquier ordenador pueda leer todos los caracteres de todos los idiomas. En concreto es ya poco habitual que no se soporten los caracteres latinos. En cualquier caso es interesante saber que HTML ofrece mecanismos para insertar estos y otros caracteres especiales en aquellos sistemas donde no están soportados.
 | Una regla mnemotécnica para recordar qué caracteres son considerados especiales por HTML es la siguiente : " Si se puede escribir un carácter pulsando sobre una sola tecla del teclado o usando como ayuda las teclas MAYÚSCULAS o ALT-GR entonces ese carácter es válido". En el teclado espańol hay que hacer tres excepciones: la letra 'ń' y los símbolos 'ż' y 'ˇ' que no son válidas. |
El mecanismo ofrecido por HTML consiste en unos códigos especiales que todos los navegadores pueden entender. A estos códigos se les llama entidades de caracteres o con el nombre inglés: character entities. Todos estos códigos comienzan por el símbolo '&' (ampersand) y terminan con el símbolo ';' (punto y coma). Puede distinguirse entre dos tipos:
Entidades de caracteres con nombre: son aquellas en las que los símbolos '&' y ';' se pone el nombre (o abreviatura) asignado a ese carácter. Sólo existen para los caracteres especiales más usados. En la figura 3.12 se puede ver un ejemplo de este tipo de entidades en el que vemos la estructura general que todas tienen.
Entidades de caracteres numéricas: en este tipo de entidades entre '&' y ';' se escribe el número asignado a ese carácter en el estándar ISO-Latin-1 precedido de una almohadilla: '#'. Este tipo de entidades son menos usadas que las anteriores aunque tienen la ventaja de abarcar cualquier letra posible en cualquier idioma. En la figura 3.13 se muestra la estructura de este tipo de entidades usando de nuevo como ejemplo la letra A mayúscula y acentuada.


4.1. Entidades de caracteres para caracteres espańoles
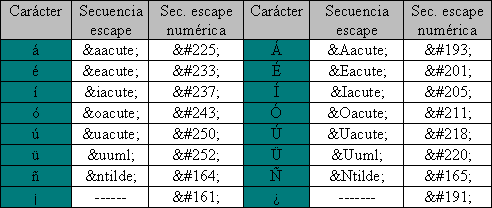
Sin duda, en Espańa los caracteres considerados cómo especiales en el resto del mundo que más se usan son los acentos, la letra eńe y los símbolos de apertura de interrogación (ż) y admiración (ˇ). En la tabla 3.1 se puede ver un un listado con dichos caracteres en los que mostramos las entidades de caracteres con nombre y numéricas que tienen asociados.
Figura 3.1. Entidades de caracteres numéricas y nominales para caracteres acentuados, 'u' con diéresis y eńe.
 | Es muy importante respetar las mayúsculas y minúsculas en las entidades de caracteres. Si se usan indistintamente el resultado obtenido no será el deseado o bien la entidad simplemente no funcionará. |
4.2. Entidades de caracteres para caracteres reservados
En el lenguaje HTML existen una serie de caracteres que tienen un significado especial. La gran mayoría de estos caracteres ya los conocemos y estamos acostumbrados a usarlos para programar un página Web. Algunos de estos caracteres son: <, >, & y ". Pero żqué ocurre si se quiere incluir alguno de estos caracteres en alguna página? Por ejemplo, si se desea escribir sobre los formatos lógicos en HTML y se quiere poner la cadena "'<B>'" en una página. Si la se pone tal cual, el navegador la confundirá con una etiqueta más y pondrá el texto siguiente en negrita. żExiste entonces alguna forma de escribir el nombre de una etiqueta? La respuesta es, obviamente, SÍ. Y la solución es usar las entidades de los caracteres reservados de HTML en vez del propio carácter. Estas entidades son las mostradas en la tabla 3.2.
Figura 3.2. Entidades de caracter numéricas y nominales para caracteres reservados del lenguaje HTML.

- Por ejemplo en vez de escribir:
Para poner texto en negrita se usa la etiqueta <B>
- Debería escribirse:
Para poner texto en negrita se usa la etiqueta <B>
Este segundo ejemplo se visualizará correctamente en el navegador, el lector está invitado a probar los dos ejemplos.
4.3. Otras entidades de caracteres
Además de las vistas hasta ahora existen otras entidades de caracteres que son de especial utilidad en la creación de páginas Web. Estos son los de la tabla 3.3
Figura 3.3. Entidades de caracteres numéricas y nominales para algunos caracteres especiales de uso común.

El espacio requiere un comentario especial. El nombre de su entidades de caracteres, nbsp, significa non breaking space que quiere decir espacio que no puede ser roto (o eliminado). Este tipo de espacios no es ignorado por los navegadores. Debe recordarse que si incluimos varios espacios en nuestra página el navegador los reduce a uno sólo, pues esto no ocurre con este tipo de espacios. Si se escribe cinco veces el navegador mostrará cinco espacios, con lo cual se pueden crear márgenes y sangrados manualmente.
 | En los archivos extra de este capítulo se incluye un listado de todos los caracteres del conjunto ISO-Latin-1 junto con sus números asociados. Este listado va en el archivo (especial.html), para que pueda ser visualizado con diferentes navegadores y en dos imágenes GIF que corresponden a la visualización de dicho archivo HTML con Internet Explorer 4.0. (escape.gif y latin1.gif). Esta información esta dividida en dos tablas, en la primera se incluyen todos aquellos caracteres que tienen una entidades de caracter nominal asociada. En una segunda tabla se incluyen todos los caracteres visualizables (por ejemplo el carácter retorno de carro no se puede ver), del ISO-Latin-1 junto con su número asociado. A partir de este número podremos construir la entidades de caracter numérica. |
| El porqué de los caracteres especiales. Explicación técnica |
|---|---|
En los comienzos de la informática se creó un código llamado ASCII (American Standard Code for Information Interchange) para representar los caracteres. Este código asignaba a cada carácter un número (de 7 bits) que al fin y al cabo es lo único con lo que un ordenador sabe trabajar. Debido al tamańo de ese número (7 bits) ese código constaba únicamente de 128 caracteres que incluía las letras, números y algunos caracteres habituales. Estos caracteres son entendidos en cualquier ordenador y por tanto pueden ser usados con libertad en un documento HTML. Con la evolución y expansión de los ordenadores pronto surgió la necesidad de ańadir nuevos caracteres, como por ejemplo aquellos específicos de cada idioma. Por esta razón se crearon extensiones del código ASCII que ańadían un bit al número asociado a cada carácter con lo que el número de caracteres representable aumentaba a 256. El problema es que no hubo un acuerdo en este ASCII extendido y se crearon varias versiones en los que había ligeras diferencias. Los documentos HTML pueden tener todo tipo de caracteres pertenecientes al IS-Latin-1 (ISO-8859-1) que es una de estas extensiones. Aún así los caracteres que no pertenezcan al código ASCII de 7 bits deben introducirse con la secuencia de escape correspondiente para evitar problemas con ordenadores que no soporten el ISO-Latin-1 sino otra extensión del ASCII. El próximo estándar del lenguaje HTML (HTML 4.0) ha llevado más lejos la extensión del código ASCII soportando el conjunto de caracteres UNICODE. Este conjunto incluye los caracteres del ASCII (a los que asigna el mismo número y por tanto es compatible), pero ańade todos los caracteres de todos los idiomas del mundo (incluidos los chinos y japoneses). Esto es importante porque UNICODE se está imponiendo como uno de los estándares del presente y del futuro. |