![[*]](crossref.png) .
.
Para resetear las estadisticas acumuladas se eliminan los valores anteriores del struct mosix_task tras apuntarlo a la tarea actual que se está tratando. mosix_clear_statistics lo implementa así :
void mosix_clear_statistics()
void
mosix_clear_statistics(void)
{
register struct mosix_task *m = ¤t->mosix;
m->ndemandpages = 0;
m->nsyscalls = 0;
m->ncopyouts = 0;
m->copyoutbytes = 0;
m->ncopyins = 0;
m->copyinbytes = 0;
m->iocounter = 0;
m->cutime = 0;
m->dctime = 0;
m->pagetime = 0;
read_lock(&tasklist_lock);
m->decsecs = 0;
read_unlock(&tasklist_lock);
spin_lock_irq(&whereto_lock);
m->last_consider = 0;
m->last_mconsider = time_now();
spin_unlock_irq(&whereto_lock);
if(m->dflags & (DREMOTE|DDEPUTY))
m->uttime = 0;
else
m->uttime = -current->times.tms_utime;
#ifdef CONFIG_MOSIX_DFSA
m->copy_ins = 0;
m->bytes_in = 0;
#endif /* CONFIG_MOSIX_DFSA */
#ifdef CONFIG_MOSIX_FS
if(m->mfs_stats)
m->mfs_stats->nnodes = 0;
#endif /* CONFIG_MOSIX_FS */
}
inline int altload()
Esta función determina la pérdida de eficiencia en la ejecución de un
nodo. La base teórica puede recuperarse de la modelización matemática,
cuando se habla de la ponderación de los nodos.
#define INFLOAD 0x8000000
#ifdef CONFIG_MOSIX_LOADLIMIT
unsigned long load_limit = 0;
unsigned long cpu_limit = 0;
inline int
altload(int load, unsigned long load_remote, unsigned long load_local,
unsigned long cpu_remote, unsigned long cpu_local,
unsigned long speed, int ncpus,
unsigned long load_limit,
unsigned long llimitmode,
unsigned long cpu_limit,
unsigned long cpulimit_mode
)
Si se da el caso que se ha definido la variable CONFIG_MOSIX_LOADLIMIT
se llamará a la función con los parámetros de configuración, sean
estos el límite de uso del procesador, la carga máxima del nodo, etc.
#else inline int altload(int load, unsigned long speed, int ncpus)Si no se han definido limitaciones para la apropiación de recursos podrá llamarse la función para que se adapte a las condiciones del sistema -a los recursos disponibles y a la carga de los mismos-. No se pasarán parámetros puesto que se gestionarán automáticamente.
#endif
{
int threshold = MF * STD_SPD / speed;
Se define el umbral como el producto entre la varibale MF -inicializada
con valor 100, es una constante obtenida por heurística en openMosix-, la
STD_SPD, que contiene un valor de referencia para las velocidades de
cada nodo y speed, que es la velocidad del nodo sobre el que se está
estudiando su rendimiento -o tiempo de ejecución-.
#if CONFIG_MOSIX_LOADLIMIT
switch(llimitmode)
{
case 0:
if (load_limit && load > load_limit)
return INFLOAD;
break;
case 1:
if (load_limit && load_remote > load_limit)
return INFLOAD;
case 2:
if (load_limit && load_local > load_limit)
return INFLOAD;
break;
}
switch(cpulimit_mode)
{
case 0:
if (cpu_limit && ((cpu_remote+cpu_local) > cpu_limit))
return INFLOAD;
break;
case 1:
if (cpu_limit && cpu_remote > cpu_limit)
return INFLOAD;
case 2:
if (cpu_limit && cpu_local > cpu_limit)
return INFLOAD;
break;
}
#endif
if(load <= threshold)
return(threshold);
if(load <= threshold + threshold/ncpus)
return(threshold + ncpus * load * (load-threshold) / threshold);
return(2 * load - threshold / ncpus);
}
Al salir de altload() se habrá obtenido el valor de retorno, que para
las distintas situaciones que se han evaluado podrá ser:
Una función importante es la choose() que concretamente se encarga de
decidir el proceso que se migrará, el bucle principal de espera de
comunicaciones y otras.
Esta función es llamada cuando ya se ha elegido el proceso a migrar y sirve para llevar la cuenta de la carga de cada nodo.
Primero calcularemos el tiempo mínimo que tardaría el proceso a ejecutarse en un nodo. La línea
mintime = MILLION * acpuse / (smp_num_cpus * MF);
es lógica puesto que la carga que pueda tener un sistema SMP de por ejemplo 8 procesadores no puede ser la misma para los mismos procesos que un sistema con 1 solo procesador por lo tanto aquíse considera el caso ideal de que la carga se divide de forma perfecta entre los procesadores.
Ahora generamos una cota inferior very_mintime, tres veces inferior a la calculada (hecho que solo supone una medida de margen). Servirá para comparaciones de valor.
Luego se calcula la carga mínima de procesador del nodo en el momento actual (para fines de ponderación y comparación con los demás nodos) y seguidamente asignamos como mejor elección la dada por el valor mínimo.
La mejor carga aún está por definir. La implementación es
very_mintime = mintime / 3;
minload = 4 * acpuse / smp_num_cpus; /* normally 4*MF */
bestpri = mintime;
bestload = -1;
Lo siguiente que se hace es ejecutar un bucle for para recorrer todas las cargas de cada nodo del cluster. En m.load es donde guardamos la información que nos llega desde otros nodos. Esta información es la que usamos para decidir si migrar un proceso o no,
Existe un número máximo de la ventana de conocimiento, una ventana de conocimiento completa (conocer todos los nodos) haría el cluster poco escalable tanto por comunicaciones como por algoritmo. Como se puede imaginar para tener una ventana de conocimiento completa, todos los nodos tendrían que enviar toda su información a todos los nodos, por lo tanto un nuevo nodo en el cluster incluiría bastante más información que enviar y no se escalaría de forma lineal (la relación número de nodos/información transmitida no sería lineal).
En cambio en la implementación de openMosix solamente se envía un número fijo de información a unos nodos elegidos aleatoriamente, esto hace que el cluster escale de forma lineal. Así mismo el algoritmo necesita procesar toda la información que tiene sobre los otros nodos para decidir si son mejores candidatos que él mismo, por lo que si el número de nodos creciera y cada uno enviara su información, la cantidad de información que se debería procesar es mayor.
Cuando se encuentra una de las estructuras con información de los nodos que coincide con el nodo al que hemos decidido enviar el proceso, se procede a actualizar los datos referentes a ese nodo para que no lo volvamos a considerar la próxima vez por no estar algo más sobrecargado.
La forma que tiene openMosix de hacerlo es una aproximación, como no tiene información directa del otro nodo hace una aproximación ruda de la carga que el proceso haría en el otro nodo.
Realmente es una carga un tanto superior (alrededor de un 2% superior) porque siempre un nodo que viene de fuera crea más carga (por ejemplo las caches de los procesadores no tienen datos de este nuevo proceso).
En la línea número 14 simplemente restamos las páginas que este proceso lleva consigo a las páginas disponibles en aquel nodo.
Este proceso ha sido elegido para la migración, pero no sabemos si ha sido
por causa de que queremos balancear la carga o de que queremos balancear
la memoria, por eso se hace unas comprobaciones, si le se elimina a m->dflags
si se está balanceando con respecto a carga (DBALANCING) o respecto a memoria
(DMBALANCING), en caso de que se esté balanceando con respecto a carga se quita ese
valor comentado y se vuelve a ejecutar la función que busca para todos
los procesos alguno que se pueda ejecutar mejor en otro nodo que en el
nodo donde actualmente se encuentran.
Como esta función lleva al actual código, mientras siga el desbalanceo de la carga se seguirá eligiendo y migrando procesos. Si la carga es de memoria se vuelve a ejecutar la función que intenta repartir justamente la memoria. Con esto nos aseguramos que migraremos suficientes procesos para que la situación vuelva a la normalidad.
En este trozo de código hemos visto como se implementa el manejo de información de carga de CPU y memoria cuando un nodo migra.
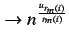 i el lector está interesado en
el algoritmo de migración deberá referirse a los ficheros
correspondientes, pues aquí se supone que la decisión ya se ha hecho y
se toma el proceso en ejecución para modificarlo y hacerlo apto para su ejecucición de
forma remota.
i el lector está interesado en
el algoritmo de migración deberá referirse a los ficheros
correspondientes, pues aquí se supone que la decisión ya se ha hecho y
se toma el proceso en ejecución para modificarlo y hacerlo apto para su ejecucición de
forma remota.
Aquí se detalla pues cómo se dividen los procesos en las dos partes: el contexto de usuario -remote- y el contexto de sistema -deputy- para iniciar la ejecución fuera del nodo local. Ante la migración de un proceso pueden darse tres situaciones, tan distintas como lo son las estratégias requeridas para abordarlas:
A continuación se abarcará cada uno de estos casos de forma separada, porque así se ha implementado en openMosix. Para cada caso pues se verá la comunicación entre las distintas partes del proceso y los diferentes nodos que aseguran que no se pierde información durante el proceso de migración, la posterior ejecución y finalmente el retorno de resultados.
Para este caso se ha implementado la función mig_local_passto_remote a la que hay que pasar como parámetros la localización del nodo remoto y la razón de la migración, a efectos de trazabilidad.
Los pasos que sigue esta función pueden enumerarse en cuatro más una fases:
En caso de proceder exitosamente se llama a deputy_migrated, en caso contrario se elimina el componente deputy con una llamada a undeputy. A continuación se analiza la implementación, véase como sigue:
int mig_local_passto_remote(int, int)
static int
mig_local_passto_remote(int whereto, int reason)
{
struct task_struct *p = current;
struct mosix_link *mlink;
int error;
int omigpages;
En el task_struct *p se guardará toda la información del proceso actual.
Se define también la estructura mosix_link
que servirá de nexo entre los nodos -más bien entre las diferentes partes
del proceso: el deputy en el local y el remote en el nodo remoto-.
if(!p->mosix.held_files && (error = mosix_rebuild_file_list()))
return(error);
lock_mosix();
write_lock_irq(&tasklist_lock);
p->mosix.remote_caps = current->cap_effective;
task_lock(p);
spin_lock(&runqueue_lock);
Han quedado bloqueados los cuatro recursos que no deben ser modificados mientras se
trabaja con la sección crítica de esta operación: guardar los
registros del proceso. Como puede verse se protege esta sección con un método de semáforos.
if(p->task_dumpable)
p->mosix.dflags |= DTDUMPABLE;
else
p->mosix.dflags &= ~DTDUMPABLE;
if(p->mm->dumpable)
p->mosix.dflags |= DDUMPABLE;
else
p->mosix.dflags &= ~DDUMPABLE;
p->mosix.dflags |= (DDEPUTY | DSYNC);
He aquí la sección crítica, que comprueba si el proceso y la memoria necesaria son migrables. En tal caso,
se marca esta opción con DUMPABLE. Hay que notar que no es hasta este
momento que se verifica si el proceso puede ser migrado. Así si por
ejemplo se trata de un proceso de emulación VM86 no es hasta este momento
que openMosix se percata que no puede aplicar la política de migración
que previamente ya ha computado.
Seguidamente se ponen los semáforos en verde.
spin_unlock(&runqueue_lock);
task_unlock(p);
write_unlock_irq(&tasklist_lock);
unlock_mosix();
Una vez hechas las comprobaciones puede procederse a hacer una copia de los
registros para que conformen el deputy.
Véase que se guardan todos los registros.
p->mosix.deputy_regs = ALL_REGISTERS;
p->mosix.pass_regs = 0;
Se comprueba que se puede establecer una conexión entre las dos divisiones
del proceso. El enlace mlink es de tipo mosix_link -tal como se
ha definido- y es la manera que tiene openMosix de crear la capa de enlace
entre los nodos con los que está interactuando.
if (!(mlink = comm_open(whereto, 0, comm_connect_timo))) {
error = -EDIST;
goto failed;
}
El parámetro whereto es el ID del nodo con el que se quiere abrir la
conexión. És útil porque mlink queda como si fuera un descriptor
de archivo y no se tiene que estar usando la dirección IP continuamente.
En caso de producirse un error, se recogerá su tipo y se sale con failed. La salida con failed implica deshacer cualquier cambio para dejar el contexto del proceso tal y como debía estar antes de iniciar cualquier intento de conexión.
Tras esto se utiliza la conexión para saber si mosix_struct realmente posee connexión. Es una llamada a comm_use.
if (comm_use(p, mlink))
panic("local_passto_remote: previous contact not null");
Se procede a hacer el recuento del número de páginas de memoria que deberán
migrarse al nodo remoto.
if(!(omigpages = p->mosix.migpages))
p->mosix.migpages = count_migrating_pages();
Se le indica al demonio de migración del nodo remoto la intención -por
parte del nodo local- de realizar una petición de migración. En la misma
operación se indica la razón de la operación.
if ((error = mig_send_request(reason, FROM_DEPUTY)))
{
p->mosix.migpages = omigpages;
goto failed;
}
Se realizará la migración efectiva de las páginas. En la primera línea se permite la
migración hacia ese nodo. En la siguiente se utiliza mig_to_send()
que es realmente quien realiza la migración -se verá con más
detalle-. En caso de error se procede como ya se ha mencionado.
release_migrations(whereto);
if (mig_do_send()) {
error = -EDIST;
p->mosix.migpages = omigpages;
goto failed;
}
p->mosix.migpages = omigpages;
deputy_startup();
return (0);
Estas últimas dos líneas dejan constancia que la migración se completó con éxito.
failed:
if(mlink)
comm_close(NULL);
undeputy(current);
return (error);
}
En el caso de que alguna operación no haya termiando satisfactoriamente se
sale con failed. Esto implica que se cierren todas la conexiones y se
llame a undeputy, el cual elimina los apsos seguidos para crear el
deputy. Resumiendo, todo vuelve al estado existente antes de iniciar la función.
En el caso que ahora se aborda el nodo local deberá alojar correctamente el proceso entrante -y remoto- para concederle los recursos que éste solicite: procesador, memoria, acceso a disco, etc. Deberán hacerse las comunicaciones pertinentes para que el proceso remoto migre al nodo local. Todo ello se implementa en la función mig_remote_passto_local.
Esta función se ejecuta también cuando se quiere que un proceso local que está siendo ejecutado en un nodo remoto sea ejecutado en el nodo local de nuevo. Para ello se vuelven a unir el remote y el deputy en la misma computadora y se verá como es la operación inversa al anterior procedimiento -como es ntaural y lógico-. Seguidamente se dará la implementación para el siguiente método:
int mig_remote_passto_local(int, int)
static int
mig_remote_passto_local(int whereto, int reason)
{
struct task_struct *p = current;
struct mig_request_h *mrp;
Se declaran dos estructuras:
int error = 0;
long orlim_as;
long orlim_rss;
long orlim_stack;
unsigned int load_came_in = 0;
mosix_deputy_rusage(0);
if(obtain_mm())
return(-EDIST);
Se ha creado una estructura para la memoria del proceso entrante y se procede con la
asignación. Esta estructura es la que maneja toda la memoria del proceso, es
muy importante para su vida en el nuevo nodo.
Seguidamente se tratarán de gaurdar los antiguos límites de memoria del proceso. Será muy necesario en el caso de que hubiera que restablecerlos a causa de algún error.
orlim_as = p->rlim[RLIMIT_AS].rlim_cur;
orlim_rss = p->rlim[RLIMIT_RSS].rlim_cur;
orlim_stack = p->rlim[RLIMIT_STACK].rlim_cur;
p->rlim[RLIMIT_AS].rlim_cur = RLIM_INFINITY;
p->rlim[RLIMIT_RSS].rlim_cur = RLIM_INFINITY;
p->rlim[RLIMIT_STACK].rlim_cur = RLIM_INFINITY;
Se enviará un mensaje al demonio de migración que se encuentra en el nodo
remoto. Se le indica lo que se quiere hacer con el proceso (DEP_COME_BACK) y
la razón por la que se quiere hacer.
if ((error = comm_send(DEP_COME_BACK, (void *) &reason, sizeof(reason),
NULL, 0, 0))) {
end_coming_in(error);
current->mosix.pages_i_bring = 0;
deputy_die_on_communication();
}
Si la llamada fallara quedaría indicado poniendo las páginas traídas
a cero. También se dejaría constancia que el deputy obtuvo un
error de comunicación.
Luego se recibirá -en el nodo local- la petición de alojamiento de la migración por parte del remoto -que habrá gestionado correctamente la llamada DEP_COME_BACK-. En caso de no recibirse, se irá a fail.
if ((error = mig_recv_request(&mrp)))
goto fail;
Se indica la inminente recepción de un nuevo proceso,
load_came_in = 1;
El canal de comunicaciones mrp que se ha usado para el control de la
comunicación ya no será para nada necesario. El canal de comunicaciones
que se usará para el envío de información -páginas- nada tiene que ver con
este canal de control del procedimiento.
comm_free((void *) mrp);
Se indica al demonio de migración que proceda con la migación.
Se manda la petición MIG_REQUEST para pedir a remote que inicie el
enviío de sus páginas.
Si no se puede comunicar con el demonio se indicará marcando que la comunicación ha muerto.
if ((error = comm_send(MIG_REQUEST|REPLY, (void *)&error, sizeof(int),
NULL, 0, 0))) {
end_coming_in(error);
current->mosix.pages_i_bring = 0;
deputy_die_on_communication();
/*NOTREACHED*/
}
Se llama a la función que lleva cabo el transporte de las páginas. Más tarde
se verá como procede. Una vez ejecutada esta función ya se ha realizado la
migración y con el siguiente código se indicará tanto lo que se quiere
hacer como el tratamiento de errores. Como se ve a continuación:
if (!(error = mig_do_receive())) {
Si se ha conseguido la migración ya no será necesario el canal de
comunicación con el demonio.
comm_close(NULL);
Ya no existe la distribución de deputy y remote, así que se
elimina la distinción.
undeputy(p);
Se quita al deputy la información sobre el
tiempo que lleva como tal -siendo deputy-, las señales, se elimina
el mosix_link con el nodo donde se encuentra el proceso, se limpian los
dflags, se elimina la lista de ficheros remotos, etc. Se termina
indicando que la operación se realizó con éxito.
mosix_clear_statistics();
#ifdef SHOW_MIGRATIONS
if(SHOW_MIGRATIONS)
printk("Wooooooooo.....\n");
#endif /*SHOW_MIGRATIONS*/
end_coming_in(0);
current->mosix.pages_i_bring = 0;
if(p->mosix.dflags & DDELAYHELD)
{
p->mosix.dflags &= ~DDELAYHELD;
mosix_rebuild_file_list();
}
return(0);
}
A continuación viene el control de errores.
fail:
p->rlim[RLIMIT_AS].rlim_cur = orlim_as;
p->rlim[RLIMIT_RSS].rlim_cur = orlim_rss;
p->rlim[RLIMIT_STACK].rlim_cur = orlim_stack;
exit_mm(p);
if(load_came_in)
{
end_coming_in(error);
current->mosix.pages_i_bring = 0;
}
return (error);
}
Al igual que en el caso anterior, si se dan errores habrá que dejarlo todo
como antes de proceder.
Ahora el esquema del método es:
int mig_remote_passto_remote(int, int)
static int
mig_remote_passto_remote(int whereto, int reason)
{
Se crearán las estructuras que permitirán empaquetar la información
tanto del proceso que debe re-migrarse como de la capa de enlace con el deputy.
struct task_struct *p = current;
struct mosix_link *newmlink = 0, *oldmlink = 0;
struct please_migrate_h pm;
int status;
int error;
p->mosix.pass_regs = 0;
Seguidamente se abrirá la nueva conexión con el nuevo nodo remoto donde se quiere hacer
llegar el proceso.
if (!(newmlink = comm_open(whereto, 0, comm_connect_timo)))
return (-EDIST);
Para las siguientes llamadas tipo comm_* se deberá
utilizar el nuevo enlace, por ser llamadas al nuevo remoto.
if (!(oldmlink = comm_use(p, newmlink)))
panic("remote_passto_remote: no previous contact");
Se comprueba la conexión desdel nuevo remoto hacia el deputy para ver
si la capa de enlace newmlink fuciona como debe. Si no lo hace, se sale
por failed.
if ((error = mig_send_request(reason, DEPUTY_PROBE)))
goto failed;
Y se copia el remote del viejo remoto a la estructura pm.
if ((error = comm_copydata((void *)&pm.ma, sizeof(pm.ma), 0)))
goto failed;
A partir de ahora se volverá a usar el antiguo canal de comunicación.
comm_use(p, oldmlink);
Se añaden a la estructura pm el destino y la razón de migración
para localizar el nuevo nodo remoto.
pm.reason = reason;
pm.to = whereto;
Se enviía la estructura pm al nuevo remoto.
mosix_deputy_rusage(0);
if ((error = deputy_request(DEP_PLEASE_MIGRATE, &pm, sizeof(pm),
NULL, 0, 0, (void **)&status, -sizeof(status))))
goto fatal;
if ((error = status))
goto failed;
Se usará el nuevo canal de comunicación. El viejo puede destruirse puesto
que las comprobaciones de que se peude trabajar con el nuevo nodo remoto han
sido satisfactorias.
comm_use(p, newmlink);
comm_close(oldmlink);
Finalmente se sale por return(0) que indica el éxito de la operación.
return (0);
Si algo no ha ido como se ha descrito, se restaura el contexto y se deshacen
los cambios.
failed:
comm_use(p, oldmlink);
comm_close(newmlink);
return (error);
fatal:
comm_use(p, oldmlink);
comm_close(newmlink);
deputy_die_on_communication();
/* NOTREACHED */
}
Las funciones que se encargan de la migración llaman a otra función llamada mig_do_send o mig_do_receive. Ya se ha comentado que estas funciones son las que realmente realizan la migración, ahora habrá que ver qué es lo que realmente se realiza en las funciones para ver como se están migrando realmente los procesos. No va a ahondarse en todas las implementaciones de las subrutinas, puesto que no suponen ninguna novedad algorítmica. Todas las funciones siguen semejantes estrategias y, como se podrá comprobar, los mismos pasos lógicos.
Así por ejemplo mig_do_send, encargada de realizar la migración efectiva de la información que requiere ser transferida, procede como sigue
int mig_do_send()
int
mig_do_send(void)
{
int credit; /* # of clean demand-pages */
Esta variable será el valor de retorno y contiene el número de páginas solicitadas.
if(current->mm->context.segments)
clear_LDT();
comm_migration_mode(1);
neutralize_my_load(1); /* don't count me: I'm going to disappear */
if(mig_send_mm_stats() || mig_send_mm_areas() ||
(credit = mig_send_pages()) < 0 ||
(current->used_math && mig_send_fp()) ||
(current->mm->context.segments && mig_send_ldt()) ||
mig_send_misc(credit))
Y si alguna de las llamadas anteriores falla
{
comm_send(MIG_NOT_COMING, NULL, 0, NULL, 0, 0);
comm_migration_mode(0);
neutralize_my_load(0);
changed_my_mind_and_staying();
return(-1);
}
/* "comm_migration_mode(0);" was done by "mig_send_misc" */
if(current->mm->context.segments)
load_LDT(current->mm);
neutralize_my_load(0);
return(0);
}
Como puede verse se divide la migración en diferentes partes según sea la naturaleza de los datos a enviar. Se irán viendo cada una de estas funciones con más detalle. En caso de que la migración falle se le indica al nodo donde se quería enviar el proceso que la migración falló enviándole un MIG_NO_COMING que indica que se procederá a abortar la migración que había sido iniciada.
Es útil para evitar que el nodo remoto tenga que estar haciendo comprobaciones sobre la integridad del proceso: será el nodo local quien sabrá qué ocurrió y así se lo indicará.
La última función deshace todo lo que se había hecho en el nodo local, el proceso que había sido elegido es deseleccionado. Se vuelve al estado anterior al que se estába cuando se elegió el proceso para ser migrado.
Antes de poder comprender la función mig_do_receive sería
necesario comprender el funcionamiento de las funciones a las que llama
mig_do_send.
Se seguirá el orden lógico de la función, y se empieza por la
implementación de la función mig_send_mm_stats.
int mig_send_mm_stats()
int
mig_send_mm_stats(void)
{
struct mm_stats_h s;
Se compara la longitud de la información entre
if(sizeof(struct mm_stats_h) !=
offsetof(struct mm_struct, env_end) -
offsetof(struct mm_struct, start_code) + sizeof(long))
panic("mig_send_mm_stats");
Se da un mensaje de pánico si la longitud no fuera la misma, hecho que solo
puede acontecerse cuando se cambie esa estructura en el kernel.
Se copian desde mm-![]() start_code todos los campos con destino la
estructura s de estados de memoria. Los campos que se copian son los referenciados
en el cuadro .
start_code todos los campos con destino la
estructura s de estados de memoria. Los campos que se copian son los referenciados
en el cuadro .
memcpy((caddr_t)&s, (caddr_t)¤t->mm->start_code, sizeof(s));
Se llamará a comm_send. Si diese algún error éste se desplazaría hasta la
función que ha llamado esta función -o séase mig_do_send- y se
abortaría.
expel_progress = 1;
return(comm_send(MIG_MM_STATS, &s, sizeof(s), NULL, 0, 0));
}
Se envía con el flag MIG_MM_STATS activado. Esto es muy importante a la hora de recibir esta información -como se verá en mig_do_receive- puesto que es lo que indica
mig_send_mm_areas()
int
mig_send_mm_areas(void)
{
struct task_struct *p = current;
register struct vm_area_struct *vma;
struct file *fp;
struct mmap_parameters_h m;
m.origin = (p->mosix.dflags & DDEPUTY) ? PE : p->mosix.deppe;
m.fixed = 1;
Definición de las estructuras necesarias:
for(vma = p->mm->mmap ; vma != NULL ; vma = vma->vm_next)
Este bucle, que iniciándose en la primera vma recorre todas las que tenga ese proceso (en particular vm_next)- indica el siguiente área virtual hasta que no hay más que entonces es NULL.
{
m.addr = vma->vm_start;
m.len = vma->vm_end - vma->vm_start;
m.flags = vma->vm_flags;
Se guarda la posición virtual en que se inicia este área, su longitud -de
esta forma sabremos cuando empieza y cuando termina- y los flags -solo
lectura, etc.- puesto que es importante conservarlos cuando se migra el
proceso a otro nodo.
Cuando un área virtual se ha creado al mapear un fichero a memoria, este área lo indica apuntando al fichero con vm_file, por lo tanto esta comprobación es cierta si el área fue creada al mapear un fichero a memoria, en ese caso se guarda la información del fichero.
if((fp = vma->vm_file))
{
struct inode *ip = fp->f_dentry->d_inode;
Se guarda el offset (o desplazamiento).
m.pgoff = vma->vm_pgoff;
Se separan los casos entre el que exiete el deputy en el nodo y entre el
que esta parte se encuentra ya en otro nodo. Esta última situación se da
cuando se migra un proceso ya migrado.
if(p->mosix.dflags & DREMOTE)
{
m.fp = home_file(fp);
m.dp = ip->u.remote_i.dp;
m.uniq = ip->u.remote_i.unique;
m.isize = ip->i_size;
m.nopage = ip->u.remote_i.nopage;
}
else
{
m.fp = vma->vm_file;
m.dp = m.fp->f_dentry;
m.uniq = ip->i_unique;
m.isize = ip->i_size;
m.nopage = vma->vm_ops->nopage;
}
}
Así según el proceso haya estado en el nodo local o en un nodo remoto
se habrá buscado la información en un lugar u en otro. Si el proceso no
era local sino remoto, se habrá buscado la información sobre el inodo del fichero
en la estructura especial de openMosix donde se guarda esta información; de
otro modo se busca la información requerida en la estructura normal usada
por el kernel.
Por supuesto en caso de que no haya sido mapeado el fichero, tenemos que indicarlo, para ello m.fp =NULL y m.pgoff=0, indicando que no existe el fichero y por lo tanto el offset es cero.
else
{
m.fp = NULL;
m.pgoff = 0;
}
Aquí se lleva a cabo el envío de información efectivo. Se puede
apreciar que la forma de enviar la información es idéntica al caso anterior:
MIG_MM_AREAS indica que la información que se envía es sobre las vma e indica que tipo
de estructura se está enviando.
if(comm_send(MIG_MM_AREA, &m, sizeof(m), NULL, 0, 0))
return(-1);
}
Como puede verse esta información se encuentra en el bucle, por lo tanto se
envía la información de cada una de las áreas.
expel_progress = 1;
return(0);
}
mig_send_pages()
int
mig_send_pages(void)
{
int credit;
credit = run_over_dirty_pages(mig_send_page, 1);
return(credit);
}
Retorna el valor credit que contiene el número de páginas con
contenido que deberán ser enviadas.
int mig_send_misc(int)
Esta función envía toda la información -y la información sobre la
información- recolectada y que abarca cualquier aspecto relacionado con las
páginas de memoria, registros y otras variables que el proceso necesitará
para ser autónomo en un nodo remoto. he aquí la implementación de la
esta última función.
int
mig_send_misc(int credit)
{
struct mig_misc_h m;
clock_t utime, stime;
extern unsigned long do_it_virt(struct task_struct *, unsigned long);
void *hd;
int hdln;
register struct task_struct *p = current;
siginfo_t *forced_sigs;
m.ptrace = p->ptrace;
m.dflags = p->mosix.dflags & (DTRACESYS1|DTRACESYS2);
memcpy((caddr_t)m.debugreg, (caddr_t)p->thread.debugreg,
sizeof(m.debugreg));
m.nice = p->nice;
m.caps = p->cap_effective;
p->mosix.remote_caps = m.caps;
m.it_prof_incr = p->it_prof_incr;
m.it_virt_incr = p->it_virt_incr;
Se enviarán los registros.
if(((p->mosix.dflags & DDEPUTY) && p->mosix.deputy_regs) ||
((p->mosix.dflags & DREMOTE) &&
p->mosix.deputy_regs != ALL_REGISTERS)) {
memcpy((caddr_t)&m.regs, (caddr_t)p->mosix.altregs, sizeof(m.regs));
} /* else do not bother - DEPUTY will bring */
m.fs = p->thread.fs;
m.gs = p->thread.gs;
Y los límites de memoria del proceso.
m.rlim_cpu = p->rlim[RLIMIT_CPU];
m.rlim_data = p->rlim[RLIMIT_DATA];
m.rlim_stack = p->rlim[RLIMIT_STACK];
m.rlim_rss = p->rlim[RLIMIT_RSS];
m.rlim_as = p->rlim[RLIMIT_AS];
#ifdef CONFIG_MOSIX_DFSA
m.rlim_nofile = p->rlim[RLIMIT_NOFILE];
m.rlim_fsz = p->rlim[RLIMIT_FSIZE];
#endif /* CONFIG_MOSIX_DFSA */
m.stay = (p->mosix.stay & DNOMIGRATE) != 0;
if(p->mosix.dflags & DDEPUTY)
{
m.deppe = PE;
m.mypid = p->pid;
memcpy(m.features, boot_cpu_data.x86_capability,
sizeof(m.features));
}
else
{
m.deppe = p->mosix.deppe;
m.mypid = p->mosix.mypid;
memcpy(m.features, p->mosix.features, sizeof(m.features));
m.passedtime = p->mosix.passedtime;
}
m.deputy_regs = p->mosix.deputy_regs;
m.deccycle = p->mosix.deccycle;
m.decay = p->mosix.decay;
m.dpolicy = p->mosix.dpolicy;
memcpy(m.depcost, deputy_here, sizeof(deputy_here));
m.depspeed = cpuspeed;
m.nmigs = p->mosix.nmigs + 1;
m.info.disclosure = p->mosix.disclosure;
m.info.uid = p->uid;
m.info.gid = p->gid;
m.info.pgrp = p->pgrp;
m.info.session = p->session;
memcpy(m.info.comm, p->comm, sizeof(m.info.comm));
m.info.tgid = p->tgid;
cli();
m.it_virt_value = p->it_virt_value;
m.it_prof_value = p->it_prof_value;
p->it_prof_value = 0;
p->it_virt_value = 0;
if(p->mosix.dflags & DDEPUTY)
m.passedtime = p->times.tms_utime + p->times.tms_stime;
utime = p->times.tms_utime;
stime = p->times.tms_stime;
m.asig.sigs = p->mosix.asig;
m.asig.nforced = p->mosix.nforced_sigs;
forced_sigs = p->mosix.forced_sigs;
m.pagecredit = credit;
m.lastxcpu = p->mosix.last_sigxcpu;
sti();
if(comm_send(MIG_MISC, &m, sizeof(m), forced_sigs,
m.asig.nforced * sizeof(siginfo_t), 0))
goto fail;
comm_migration_mode(0);
expel_progress = 1;
if(comm_recv(&hd, &hdln) == (MIG_MISC|REPLY))
return(0); /* commit point */
fail:
cli();
p->it_prof_value = m.it_prof_value;
p->it_virt_value = m.it_virt_value;
/* maintain accurate correlation between process-times and timers: */
utime = p->times.tms_utime - utime;
stime = p->times.tms_stime - stime;
sti();
if(utime > 0)
{
extern rwlock_t xtime_lock;
write_lock_irq(&xtime_lock);
do_it_virt(p, utime);
write_unlock_irq(&xtime_lock);
}
if(!(p->mosix.dflags & DDEPUTY) && /* (DEPUTY gets it in "depticks") */
utime + stime > 0)
absorb_deptime(utime + stime);
return(-1);
}
int mig_do_receive()
Esta función gestionará toda recepción de los flags definidos en
openMosix. Esto conlleva y completo control de la situación puesto que cada
tipo de definición resume el problema que haya podido darse o proseguir con
el diálogo con la otra parte del proceso para asegurar una correcta comunicación..
int
mig_do_receive(void)
{
struct mosix_task *m = ¤t->mosix;
int type;
void *head;
int hlen;
int (*mmap_func)(struct mmap_parameters_h *, int);
unsigned int got_not_coming = 0;
spin_lock_irq(&runqueue_lock);
m->dflags |= DINCOMING;
spin_unlock_irq(&runqueue_lock);
current->used_math = 0;
while(1) {
switch(type = comm_recv(&head, &hlen)) {
case MIG_MM_STATS:
mig_do_receive_mm_stats((struct mm_stats_h *)head);
break;
case MIG_MM_AREA:
if(m->dflags & DREMOTE)
mmap_func = remote_mmap;
else
mmap_func = deputy_remmap;
if(mmap_func((struct mmap_parameters_h *)head, 1))
{
comm_free(head);
goto fail;
}
break;
case MIG_PAGE:
if(mig_do_receive_page(*((unsigned long *)head)))
{
comm_free(head);
goto fail;
}
break;
case MIG_FP:
mig_do_receive_fp((union i387_union *)head);
break;
case MIG_XFP:
mig_do_receive_xfp((union i387_union *)head);
break;
case MIG_LDT:
if(mig_do_receive_ldt())
{
comm_free(head);
goto fail;
}
break;
case MIG_MISC:
mig_do_receive_misc((struct mig_misc_h *)head);
comm_free(head);
spin_lock_irq(&runqueue_lock);
m->dflags &= ~DINCOMING;
spin_unlock_irq(&runqueue_lock);
flush_tlb(); /* for all the new pages */
comm_send(MIG_MISC|REPLY, NULL, 0, NULL, 0, 0);
return(0);
case MIG_NOT_COMING:
got_not_coming = 1;
goto fail;
default:
if(m->dflags & DDEPUTY)
deputy_communication_failed();
comm_free(head);
goto fail;
}
comm_free(head);
if((m->dflags & DREMOTE) && (mosadmin_mode_block || !NPE))
goto fail;
}
fail:
if(type >= 0)
comm_flushdata(COMM_ALLDATA);
spin_lock_irq(&runqueue_lock);
m->dflags &= ~DINCOMING;
spin_unlock_irq(&runqueue_lock);
if((m->dflags & DDEPUTY) && !got_not_coming)
{
/* receiving all the debris can take time and
someone may need the memory meanwhile! */
current->mosix.pages_i_bring = 0;
do_munmap(current->mm, 0, PAGE_OFFSET, 1);
while((type = comm_recv(&head, &hlen)) >= 0 &&
type != MIG_NOT_COMING)
{
comm_free(head);
comm_flushdata(COMM_ALLDATA);
if(type == MIG_MISC)
/* send anything but MIG_MISC|REPLY: */
/* they will then send MIG_NOT_COMING! */
comm_send(DEP_SYNC, NULL, 0, NULL, 0, 0);
}
}
return(-1);
}
struct uplist {
struct uplist *next;
unsigned short pe;
short age;
};
#ifdef CONFIG_MOSIX_LOADLIMIT
extern unsigned long load_limit;
extern unsigned long cpu_limit;
extern unsigned long mosadmin_mode_loadlimit;
extern unsigned long mosadmin_mode_cpulimit;
#endif
static struct uplist uplist[MAXKNOWNUP];
static struct uplist *uphead, *upfree;
static int info_nup; /* number of processes in uplist */
struct loadinfo loadinfo[INFO_WIN];
static int info_recv_message(struct infomsg *, int);
static int info_send_message(int, struct infomsg *);
static void update_uplist(struct loadinfo *);
static void update_window(struct loadinfo *);
static void inform(void);
static void not_responding(int);
static void age_uplist(void);
static int rand(int, int);
static char INFODSTR[] = "oM_infoD";
#define INFO_BUFSIZE 8192
int
mosix_info_daemon(void *nothing)
{
struct task_struct *p = current;
struct loadinfo *load;
struct infomsg *msg;
static char info_buf[INFO_BUFSIZE]; /* (large) buffer for info load */
common_daemon_setup(INFODSTR, 1);
lock_mosix();
info_proc = current;
unlock_mosix();
restart:
wait_for_mosix_configuration(&info_daemon_active);
comm_init_linkpool();
if (!p->mosix.contact) {
comm_use(p, comm_open(COMM_INFO, 0, 0UL));
if (!p->mosix.contact)
{
printk("%s: failed comm_open - exiting\n", INFODSTR);
comm_free_linkpool();
if(p->mosix.contact)
comm_close(NULL);
lock_mosix();
info_daemon_active = 0;
info_proc = NULL;
unlock_mosix();
do_exit(0);
}
}
msg = (struct infomsg *) info_buf;
load = (struct loadinfo *) &msg->load;
while (1) {
comm_wait();
/* if openMosix was shut down - restart everything */
if (!PE) {
comm_close(NULL);
comm_free_linkpool();
goto restart;
}
while (info_recv_message(msg, INFO_BUFSIZE))
{
update_uplist(load);
update_window(load);
if (!mosadmin_mode_quiet) {
load_balance();
memory_balance();
}
}
if(sigismember(&p->pending.signal, SIGALRM))
{
spin_lock_irq(&p->sigmask_lock);
flush_signals(p);
spin_unlock_irq(&p->sigmask_lock);
if(mosadmin_mode_quiet)
continue;
if(PE)
inform();
inc_decays();
comm_age_linkpool();
age_uplist();
loadinfo[0].mem = latest_free_mem;
loadinfo[0].rmem = nr_free_pages();
age_balancing();
}
}
}
static void
age_uplist(void)
{
struct uplist *up, *prev, *cutpoint;
int old = 10 * (NPE-1);
/* (the more nodes around, the less often they are
* likely to come up again, so we hold them longer) */
if(old > 32767)
old = 32767;
spin_lock(&uplist_lock);
for (prev = NULL, up = uphead; up; prev = up , up = up->next)
if (++up->age >= old)
{
/* the list is sorted by age, so all the rest are too old! */
if (prev)
prev->next = NULL;
else
uphead = NULL;
cutpoint = up;
while(1)
{
info_nup--;
if(up->next)
up = up->next;
else
break;
}
prev = upfree;
upfree = cutpoint;
up->next = prev;
break;
}
spin_unlock(&uplist_lock);
}
static void
update_uplist(struct loadinfo *load)
{
struct uplist *up, *prev;
spin_lock(&uplist_lock);
for (prev = NULL , up = uphead ; up ; prev = up , up = up->next)
if (up->pe == load->pe)
{
up->age = 0;
if (prev) /* put it first */
{
prev->next = up->next;
up->next = uphead;
uphead = up;
}
break;
}
if (!up) {
if (upfree) {
up = upfree;
upfree = upfree->next;
info_nup++;
} else {
for (prev = uphead ; prev->next->next ;
prev = prev->next)
; /* nothing */
up = prev->next;
prev->next = NULL;
}
up->pe = load->pe;
up->age = 0;
up->next = uphead;
uphead = up;
}
spin_unlock(&uplist_lock);
schedule(); /* since a lot of time passed, let's see if there is anything to run in the meantime */
}
static void
update_window(struct loadinfo *load)
{
static int info_slot; /* pointer to next information to fill */
unsigned int i;
info_slot = (info_slot % (INFO_WIN - 1)) + 1;
loadinfo[info_slot] = *load;
for (i = 1 ; i < INFO_WIN ; i++)
if (i != info_slot && loadinfo[i].pe == load->pe)
{
write_lock_bh(&loadinfo_lock);
loadinfo[i].pe = 0;
write_unlock_bh(&loadinfo_lock);
break;
}
}
#define speed_adjust(x) ((x) * ((int64_t)STD_SPD) / loadinfo[0].speed)
void
info_update_costs(void)
{
register unsigned int i;
write_lock_bh(&loadinfo_lock);
for(i = 0 ; i < MAX_MOSIX_TOPOLOGY ; i++)
{
#ifdef CONFIG_MOSIX_TOPOLOGY
loadinfo[0].costs[i].page = mosix_cost[i].PAGE_R;
loadinfo[0].costs[i].syscall = mosix_cost[i].SYSCALL_R;
loadinfo[0].costs[i].out = mosix_cost[i].COPYOUT_BASE_R;
loadinfo[0].costs[i].outkb = mosix_cost[i].COPYOUT_PER_KB_R;
loadinfo[0].costs[i].in = mosix_cost[i].COPYIN_BASE_R;
loadinfo[0].costs[i].inkb = mosix_cost[i].COPYIN_PER_KB_R;
loadinfo[0].costs[i].first = mosix_cost[i].first;
loadinfo[0].costs[i].last = mosix_cost[i].last;
#else
remote_here.page = mosix_cost[i].PAGE_R;
remote_here.syscall = mosix_cost[i].SYSCALL_R;
remote_here.out = mosix_cost[i].COPYOUT_BASE_R;
remote_here.outkb = mosix_cost[i].COPYOUT_PER_KB_R;
remote_here.in = mosix_cost[i].COPYIN_BASE_R;
remote_here.inkb = mosix_cost[i].COPYIN_PER_KB_R;
#endif /* CONFIG_MOSIX_TOPOLOGY */
remote_here_adjusted[i].page =
speed_adjust(mosix_cost[i].PAGE_R);
remote_here_adjusted[i].syscall =
speed_adjust(mosix_cost[i].SYSCALL_R);
remote_here_adjusted[i].out =
speed_adjust(mosix_cost[i].COPYOUT_BASE_R);
remote_here_adjusted[i].outkb =
speed_adjust(mosix_cost[i].COPYOUT_PER_KB_R);
remote_here_adjusted[i].in =
speed_adjust(mosix_cost[i].COPYIN_BASE_R);
remote_here_adjusted[i].inkb =
speed_adjust(mosix_cost[i].COPYIN_PER_KB_R);
#ifdef CONFIG_MOSIX_TOPOLOGY
remote_here_adjusted[i].first = mosix_cost[i].first;
remote_here_adjusted[i].last = mosix_cost[i].last;
#endif /* CONFIG_MOSIX_TOPOLOGY */
}
write_unlock_bh(&loadinfo_lock);
}
void
info_update_mfscosts(void)
{
#ifdef CONFIG_MOSIX_TOPOLOGY
memcpy(loadinfo[0].mfscosts, mfs_cost, sizeof(mfs_cost));
#endif /* CONFIG_MOSIX_TOPOLOGY */
}
#ifdef CONFIG_MOSIX_LOADLIMIT
void set_loadlimit(void)
{
write_lock_bh(&loadinfo_lock);
loadinfo[0].load_limit = load_limit;
write_unlock_bh(&loadinfo_lock);
}
void set_loadlimitmode(void)
{
write_lock_bh(&loadinfo_lock);
loadinfo[0].llimitmode = mosadmin_mode_loadlimit;
write_unlock_bh(&loadinfo_lock);
}
void set_cpulimitmode(void)
{
write_lock_bh(&loadinfo_lock);
loadinfo[0].cpulimitmode = mosadmin_mode_cpulimit;
write_unlock_bh(&loadinfo_lock);
}
void set_cpulimit(void)
{
write_lock_bh(&loadinfo_lock);
loadinfo[0].cpu_limit = cpu_limit;
write_unlock_bh(&loadinfo_lock);
}
#endif
void
set_my_cpuspeed(void)
{
int s = cpuspeed;
if(sizeof(loadinfo[0].speed) < 4 && s > 65535)
{
printk("Computer Too Fast! Time to Update Standard-Speed.\n");
s = 65535;
}
stable_export = (MF+2) * STD_SPD / (s * smp_num_cpus);
if(stable_export == MF * STD_SPD / (s * smp_num_cpus))
stable_export++;
write_lock_bh(&loadinfo_lock);
loadinfo[0].speed = s;
write_unlock_bh(&loadinfo_lock);
info_update_costs();
info_update_mfscosts();
}
void
info_init(void)
{
loadinfo[0].ncpus = smp_num_cpus;
loadinfo[0].tmem = num_physpages;
set_my_cpuspeed();
}
void
info_startup(void)
{
unsigned int i;
info_seed1 = PE;
info_seed2 = PE*PE*PE*PE;
write_lock_bh(&loadinfo_lock);
loadinfo[0].pe = PE;
for (i = 1 ; i < INFO_WIN ; i++) {
loadinfo[i].pe = 0;
loadinfo[i].load = 0xffffffff;
}
write_unlock_bh(&loadinfo_lock);
spin_lock(&uplist_lock);
upfree = uphead = NULL;
info_nup = 0;
memset(uplist, 0, sizeof(struct uplist) * MAXKNOWNUP);
for (i = 0; i < MAXKNOWNUP; i++) {
uplist[i].next = upfree;
upfree = &uplist[i];
}
spin_unlock(&uplist_lock);
}
void
info_reconfig()
{
unsigned int i;
struct uplist *up, *prev;
lock_mosix(); /* because "mos_to_net" does! */
spin_lock(&uplist_lock);
recheck:
prev = NULL;
for (up = uphead ; up ; prev = up, up = up->next)
if (!mos_to_net(up->pe, NULL)) {
if (prev)
prev->next = up->next;
else
uphead = up->next;
up->next = upfree;
upfree = up;
info_nup--;
goto recheck;
}
spin_unlock(&uplist_lock);
write_lock_bh(&loadinfo_lock);
for (i = 1; i < INFO_WIN; i++)
if (loadinfo[i].pe && !mos_to_net(loadinfo[i].pe, NULL))
loadinfo[i].pe = 0;
write_unlock_bh(&loadinfo_lock);
unlock_mosix();
}
static int
info_recv_message(struct infomsg *info, int bufsize)
{
static mosix_addr ra; /* reply address */
struct mosix_link *l = current->mosix.contact;
struct loadinfo *load = &(info->load);
int n;
int sender;
while (1) {
n = comm_recvfrom(info, bufsize, l, &ra, 0);
if (n == -EDIST)
continue; /* message > bufsize */
if (n < 0)
return (0);
if (n < sizeof(*info)) {
continue;
}
if (info->version != MOSIX_BALANCE_VERSION) {
continue;
}
if (info->topology != MAX_MOSIX_TOPOLOGY) {
continue;
}
sender = load->pe ? : load->speed;
if (sender > MAXPE || sender != net_to_mos(&ra)) {
continue;
}
if (sender == PE)
{
printk("WARNING: Another computer is masquerading as same openMosix node as this (%d)!\n", PE);
continue;
}
if (load->pe)
return (1);
/*
* Ugly convention: !load->pe ==> this is a GETLOAD request
*/
lock_mosix();
write_lock_bh(&loadinfo_lock);
loadinfo[0].status = my_mosix_status();
loadinfo[0].free_slots = get_free_guest_slots();
unlock_mosix();
loadinfo[0].mem = latest_free_mem;
loadinfo[0].rmem = nr_free_pages();
loadinfo[0].util = acpuse;
#ifdef CONFIG_MOSIX_LOADLIMIT
loadinfo[0].load_limit = load_limit;
loadinfo[0].cpu_limit = cpu_limit;
loadinfo[0].llimitmode = mosadmin_mode_loadlimit;
loadinfo[0].cpulimitmode = mosadmin_mode_cpulimit;
#endif
#ifdef CONFIG_MOSIX_RESEARCH
loadinfo[0].rio = io_read_rate;
loadinfo[0].wio = io_write_rate;
#endif /* CONFIG_MOSIX_RESEARCH */
*load = loadinfo[0];
write_unlock_bh(&loadinfo_lock);
comm_sendto(COMM_TOADDR, info, sizeof(*info), l, &ra);
}
return(0);
}
static int
info_send_message(int mos, struct infomsg *info)
{
return(comm_sendto(mos, info, sizeof(*info), current->mosix.contact,
NULL) < 0);
}
int
load_to_mosix_info(struct loadinfo l, struct mosix_info *info, int touser)
{
struct mosix_info tmp, *uaddr;
int error;
if(touser)
{
uaddr = info;
info = &tmp;
}
else
uaddr = NULL; /* pacify angry stupid gcc */
info->load = ((int64_t)l.load) * standard_speed / STD_SPD;
#ifdef CONFIG_MOSIX_LOADLIMIT
info->load_limit = l.load_limit;
info->llimitmode = l.llimitmode;
info->loadlocal = l.loadlocal;
info->loadremote = l.loadremote;
info->cpulimitmode = l.cpulimitmode;
info->cpu_limit = l.cpu_limit;
info->cpulocal = l.cpulocal;
info->cpuremote = l.cpuremote;
#endif
info->speed = l.speed;
info->ncpus = l.ncpus;
info->mem = l.mem * PAGE_SIZE;
info->rmem = l.rmem * PAGE_SIZE;
info->tmem = l.tmem * PAGE_SIZE;
info->util = l.util;
info->status = l.status;
if(touser && (error = copy_to_user((char *)uaddr, (char *)info,
sizeof(*info))))
return(-EFAULT);
return(0);
}
static int info_serialno = 0;
static int info_timo;
static int info_retry;
static int info_retry_cnt;
#define INFO_TIMO 50000 /* ms */
#define INFO_RETRY 20000 /* after 20 & 40 ms */
#define SIMULTANEOUS_QUERIES 10
void
mosinfo_update_gateways(void)
{
/* the following may be further optimized in the future: */
info_timo = INFO_TIMO * (mosadmin_gateways + 1);
#if INFO_RETRY * 3 > 65535
#error: "timtosend" below must be made "unsigned int".
#endif
info_retry = INFO_RETRY * (mosadmin_gateways + 1);
info_retry_cnt = (info_timo + info_retry - 1) / info_retry;
}
int
balance_get_infos(int first, int num, struct mosix_info *info, int touser)
{
char *donebits, fewbits[20]; /* 20*8=160 seems to cover most cases */
struct progress
{
unsigned short node;
unsigned short timtosend;
unsigned int timo;
int serialno;
} progress[SIMULTANEOUS_QUERIES];
unsigned int hint = 0;
unsigned int ntaken = 0;
unsigned int ndone = 0;
unsigned int inpot = 0;
int node, from, n;
unsigned int i;
int error = 0;
int timo;
now_t before;
mosix_link *mlink;
struct loadinfo l;
struct infomsg infomsg;
if(num <= 8*sizeof(fewbits))
donebits = fewbits;
else if(!(donebits = (char *)kmalloc((num+7)/8, GFP_KERNEL)))
return(-ENOMEM);
memset(donebits, 0, (num+7)/8);
if (!(mlink = comm_borrow_linkpool()))
error = -EDIST;
loop:
while(!error && ndone < num)
{
while(inpot < SIMULTANEOUS_QUERIES && ntaken < num)
{
while(donebits[hint/8] & (1 << (hint%8)))
if(++hint == num)
hint = 0;
donebits[hint/8] |= (1 << (hint%8));
ntaken++;
node = first + hint;
if (node == PE)
{
read_lock_bh(&loadinfo_lock);
l = loadinfo[0];
read_unlock_bh(&loadinfo_lock);
l.status = my_mosix_status();
#ifdef CONFIG_MOSIX_LOADLIMIT
l.load_limit = load_limit;
l.llimitmode = mosadmin_mode_loadlimit;
l.cpulimitmode = mosadmin_mode_cpulimit;
l.cpu_limit = cpu_limit;
#endif
l.util = acpuse;
#ifdef CONFIG_MOSIX_RESEARCH
l.rio = io_read_rate;
l.wio = io_write_rate;
#endif /* CONFIG_MOSIX_RESEARCH */
ready_immediate:
ndone++;
if((error = load_to_mosix_info(l, &info[hint],
touser)))
break;
continue;
}
if (!mos_to_net(node, NULL))
{
l.status = 0;
goto ready_immediate;
}
progress[inpot].node = node;
progress[inpot].timo = info_timo;
progress[inpot].timtosend = 0;
progress[inpot].serialno = info_serialno++;
inpot++;
}
if(error || ndone == num)
break;
timo = info_retry;
for(i = 0 ; i < inpot ; i++)
{
if(progress[i].timo < timo)
timo = progress[i].timo;
if(progress[i].timo && progress[i].timtosend <= 0)
{
progress[i].timtosend = info_retry;
infomsg.version = MOSIX_BALANCE_VERSION;
infomsg.serialno = progress[i].serialno;
infomsg.topology = MAX_MOSIX_TOPOLOGY;
infomsg.load.pe = 0; /* eg. GETLOAD */
infomsg.load.speed = PE;
if(comm_sendto(progress[i].node, &infomsg,
sizeof(infomsg), mlink, NULL) <= 0)
{
node = progress[i].node;
progress[i] = progress[--inpot];
ndone++;
l.status = DS_MOSIX_DEF;
error = load_to_mosix_info(l,
&info[node - first], touser);
goto loop;
}
}
if(progress[i].timtosend < timo)
timo = progress[i].timtosend;
}
before = time_now();
n = comm_recvfrompe(&infomsg, sizeof(infomsg), mlink, &from,
info_retry);
if (n == sizeof(infomsg))
for (i = 0; i < inpot; i++) {
if (from == progress[i].node &&
infomsg.load.pe == progress[i].node &&
infomsg.serialno == progress[i].serialno) {
ndone++;
node = progress[i].node;
progress[i] = progress[--inpot];
error = load_to_mosix_info(infomsg.load,
&info[node - first], touser);
break;
}
} else if (signal_pending(current))
error = -EINTR;
if (error)
break;
before = time_since(before);
if(before > timo)
before = timo;
if(before)
for(i = 0 ; i < inpot ; i++)
{
progress[i].timo -= before;
if(progress[i].timtosend < before)
progress[i].timtosend = 0;
else
progress[i].timtosend -= before;
}
if(n <= 0)
for(i = 0 ; i < inpot ; i++)
if(progress[i].timo <= 0) /* cannot realy be < */
{
node = progress[i].node;
progress[i] = progress[--inpot];
ndone++;
l.status = DS_MOSIX_DEF;
if((error = load_to_mosix_info(l,
&info[node - first], touser)))
break;
i--;
}
}
if (mlink)
comm_return_linkpool(mlink);
if(num > 8*sizeof(fewbits))
kfree(donebits);
return(error);
}
int
balance_ask_node(int node, struct infomsg *info)
{
mosix_link *mlink = NULL;
int from, n, error = 0;
int serialno;
int tries;
now_t before;
int timo;
if (!(mlink = comm_borrow_linkpool()))
error = -EDIST;
serialno = info_serialno++;
tries = info_retry_cnt;
timo = info_retry;
while (!error && tries--) {
info->version = MOSIX_BALANCE_VERSION;
info->serialno = serialno;
info->topology = MAX_MOSIX_TOPOLOGY;
info->load.pe = 0; /* eg. GETLOAD */
info->load.speed = PE;
error = comm_sendto(node, info, sizeof(*info), mlink, NULL);
if (error < sizeof(*info))
{
if(error >= 0)
error = -EDIST;
goto out;
}
error = 0;
before = time_now();
n = comm_recvfrompe(info, sizeof(*info), mlink, &from, timo);
if (n == sizeof(*info) && from == node &&
info->load.pe == node && info->serialno == serialno)
goto out;
before = time_since(before);
if(before < timo)
{
timo -= before;
tries++;
}
else
timo = info_retry;
}
error = -EAGAIN;
out:
if (mlink)
comm_return_linkpool(mlink);
return (error);
}
int
balance_get_info(int node, struct mosix_info *info)
{
struct infomsg infomsg;
int error;
if (node == PE || node == 0) /* local info */
{
read_lock_bh(&loadinfo_lock);
infomsg.load = loadinfo[0];
read_unlock_bh(&loadinfo_lock);
infomsg.load.status = my_mosix_status();
#ifdef CONFIG_MOSIX_LOADLIMIT
infomsg.load.load_limit = load_limit;
infomsg.load.llimitmode = mosadmin_mode_loadlimit;
infomsg.load.cpulimitmode = mosadmin_mode_cpulimit;
infomsg.load.cpu_limit = cpu_limit;
#endif
infomsg.load.util = acpuse;
#ifdef CONFIG_MOSIX_RESEARCH
infomsg.load.rio = io_read_rate;
infomsg.load.wio = io_write_rate;
#endif /* CONFIG_MOSIX_RESEARCH */
load_to_mosix_info(infomsg.load, info, 0);
}
else if (!mos_to_net(node, NULL))
info->status = 0;
else if((error = balance_ask_node(node, &infomsg)))
{
info->status = DS_MOSIX_DEF;
return(error);
}
else
load_to_mosix_info(infomsg.load, info, 0);
return(0);
}
int
balance_get_load(int node, struct loadinfo *l)
{
struct infomsg infomsg;
if (node == PE || node == 0)
{
*l = loadinfo[0];
return(0);
}
else if (!mos_to_net(node, NULL))
return(-1);
else if(balance_ask_node(node, &infomsg))
return(-1);
*l = infomsg.load;
return(0);
}
static void
inform()
{
int to;
int i;
struct uplist *up;
struct infomsg info;
info.version = MOSIX_BALANCE_VERSION;
info.topology = MAX_MOSIX_TOPOLOGY;
info.serialno = 0; /* meaning no serial number */
write_lock_bh(&loadinfo_lock);
loadinfo[0].free_slots = get_free_guest_slots();
info.load = loadinfo[0];
write_unlock_bh(&loadinfo_lock);
info.load.load = export_load;
/* first select any node, and send the load */
lock_mosix();
to = (NPE > 1) ? nth_node(rand(NPE-1, 1)) : 0;
unlock_mosix();
if(to && info_send_message(to, &info))
not_responding(to);
/* then select a node that seems to be up */
spin_lock(&uplist_lock);
if (info_nup)
{
for (up = uphead , i = rand(info_nup, 0) ; i-- ; up = up->next)
; /* just stop at random element */
to = (up->pe == to) ? 0 : up->pe;
}
else
to = 0;
spin_unlock(&uplist_lock);
if (to && info_send_message(to, &info))
not_responding(to);
}
void
not_responding(int pe)
{
unsigned int i;
struct uplist *up, *prev;
spin_lock(&uplist_lock);
prev = NULL;
for (up = uphead ; up ; prev = up , up = up->next)
if (up->pe == pe)
{
if (prev)
prev->next = up->next;
else
uphead = up->next;
up->next = upfree;
upfree = up;
info_nup--;
break;
}
spin_unlock(&uplist_lock);
write_lock_bh(&loadinfo_lock);
for (i = 1; i < INFO_WIN; i++)
if (loadinfo[i].pe == pe)
loadinfo[i].pe = 0;
write_unlock_bh(&loadinfo_lock);
}
void
this_machine_is_favourite(int which)
{
register struct uplist *up;
spin_lock(&uplist_lock);
for(up = uphead ; up ; up = up->next)
if(up->pe == which)
break;
if(!up && upfree)
#ifdef CONFIG_MOSIX_CHEAT_MIGSELF
if(which != PE)
#endif /* CONFIG_MOSIX_CHEAT_MIGSELF */
{
up = upfree;
upfree = upfree->next;
up->next = uphead;
up->pe = which;
up->age = 0;
uphead = up;
info_nup++;
}
spin_unlock(&uplist_lock);
}
static int
rand(int modulo, int regen)
{
if(regen)
{
info_seed2++;
/* alternating even/odd values: */
info_seed1 = info_seed1*info_seed2 + 1;
return((info_seed1 & 0x7fffffff) % modulo);
}
else
return((((info_seed2+1)*info_seed1+1) & 0x7fffffff) % modulo);
}
/*
* we are 99.99% going to migrate and let other processes be migrated,
* but not before we adjust the local and remote loads to discourage
* further migrations.
*/
void
release_migrations(int whereto)
{
register struct mosix_task *m = ¤t->mosix;
register int load;
unsigned int i;
int pages = m->migpages ? : count_migrating_pages();
this_machine_is_favourite(whereto);
/* Decrease the local load by the load caused by this process,
* to avoid over-migration.
*/
write_lock_bh(&loadinfo_lock);
spin_lock_irq(&runqueue_lock);
load = m->load * STD_SPD / 4 / cpuspeed;
load /= smp_num_cpus;
/* It is ON PURPOSE that `acpuse' is not taken into account */
if(loadinfo[0].load < load) /* should not happen, but ... */
load = loadinfo[0].load;
load_left += load;
spin_unlock_irq(&runqueue_lock);
loadinfo[0].load -= load;
/* increase the receiver's-load */
for(i = 1 ; i < INFO_WIN ; i++)
if(loadinfo[i].pe == whereto)
{
/* add slightly more than 1 process worth of load */
loadinfo[i].load += MF * 102 * STD_SPD/
(loadinfo[i].speed * loadinfo[i].ncpus * 100);
loadinfo[i].mem -= pages;
break;
}
write_unlock_bh(&loadinfo_lock);
m->pages_i_bring = -pages; /* discourage 'memory_badly_required' */
unchoose_me();
}
void
info_someone_came_in(void)
{
write_lock_bh(&loadinfo_lock);
coming_in++;
came_lately4 += 4;
export_load += MF * STD_SPD / (smp_num_cpus * cpuspeed);
write_unlock_bh(&loadinfo_lock);
}
void
end_coming_in(int error)
{
write_lock_bh(&loadinfo_lock);
coming_in--;
if(error)
{
if((int)(came_lately4 -= 4) < 0)
came_lately4 = 0;
}
write_unlock_bh(&loadinfo_lock);
}
La estructura más importante quizás sea la que define la capa de enlace
struct mosix_link {
/* the first 2 elements are common to both types and must stay there */
struct socket *sock; /* socket para comunicaciones */
int flags; /* flags de estado */
int dlen; /* longitud de los datos pendientes */
int peer; /* mosix ID del nodo # of peer */
char *hideptr; /* puntero a los datos del proceso en curso */
char *hidebuf; /* puntero a la posici\'on del buffer para los datos */
int hidelen; /* longitud de los datos en el buffer */
char head[COMM_DEF_HEADSIZE];
};
mosix_link *comm_open()
Abre un socket para las comunicaciones de openMosix.
El tipo de conexión puede variar, se define para el entero pasado por
parámetro mos la siguiente relación:
Véase la implementación:
mosix_link *
comm_open(int mos, mosix_addr *maddr, unsigned long timo)
{
int error = -EDIST;
struct socket *sock = NULL;
mosix_link *mlink = NULL;
struct sockaddr sa;
int connect = 1, bind = 1, need_comm = 1, listen = 1, peer = 0;
struct sockaddr *saddr = &(maddr->saddr);
DECLARE_WAITQUEUE(wait, current);
/* tabla de los flags para cada caso
* COMM_INFO: connect = 0, need_comm = 0, listen = 0, bind = 1
* COMM_MIGD: connect = 0, need_comm = 1, listen = 1, bind = 1
* COMM_ACCEPT: connect = 0, need_comm = 1, listen = 1, bind = 1
* COMM_TOADDR: connect = 1, need_comm = 1, listen = 0, bind = 1
* COMM_LOOSE: connect = 0, need_comm = 0, listen = 0, bind = 0
* default: connect = 1, need_comm = 1, listen = 1, bind = 1
*/
switch (mos) {
case COMM_LOOSE:
bind = 0;
/* fall through */
case COMM_INFO:
listen = 0;
/* fall through */
case COMM_MIGD:
need_comm = 0;
/* fall through */
case COMM_ACCEPT:
connect = 0;
if(!saddr)
saddr = &sa;
break;
case COMM_TOADDR:
if(saddr->sa_family != AF_INET)
return(NULL);
break;
default:
peer = mos;
saddr = &sa;
break;
}
DISABLE_EVENTS();
/* fill in socket address and allocate a socket */
if (!(sock = comm_set_address(mos, saddr, 1)))
goto failed;
if (need_comm) { /* si se requiere mosix_link */
mlink = kmalloc(sizeof(mosix_link), GFP_KERNEL);
if (!mlink) {
no_memory:
goto failed;
}
mlink->flags = COMM_FULLLINK;
comm_setup_link(mlink, peer);
} else {
mlink = kmalloc(sizeof(struct socket *) + sizeof(int),
GFP_KERNEL);
if (!mlink)
goto no_memory;
mlink->flags = COMM_INFOLINK;
}
mlink->sock = sock;
if ((error = comm_setup_socket(sock, mos)))
goto failed;
if (!connect) { /* configuracion para mantenerse a la escucha de comunicaciones */
if(bind)
{
error = sock->ops->bind(sock, saddr, sizeof(*saddr));
if (error) {
if(error == -EADDRINUSE && mos == COMM_MIGD)
printk("Migration port (%d) Already in use\n", ntohs(MIG_DAEMON_PORT));
goto failed;
}
}
if (listen) { /* se solicita una comunicacion? */
error = sock->ops->listen(sock, SOMAXCONN);
if (error) {
goto failed;
}
}
if (mos == COMM_ACCEPT) {
mlink->flags |= COMM_WAITACCEPT;
if ((error = comm_getname(sock, saddr))) {
goto failed;
}
}
} else { /* configuracion para iniciar una comunicacion */
if (!timo)
timo = MAX_SCHEDULE_TIMEOUT;
error = sock->ops->connect(sock, saddr, sizeof(*saddr),
O_NONBLOCK);
add_wait_queue(sock->sk->sleep, &wait);
while (sock->state != SS_CONNECTED) {
set_current_state(TASK_INTERRUPTIBLE);
error = sock->ops->connect(sock, saddr, sizeof(*saddr),
O_NONBLOCK);
if (error != -EALREADY || (error=sock_error(sock->sk)))
break;
timo = schedule_timeout(timo);
if (timo <= 0) {
error = -EAGAIN;
break;
}
}
remove_wait_queue(sock->sk->sleep, &wait);
set_current_state(TASK_RUNNING);
if (error) {
goto failed;
}
if (sock->sk->err) {
error = sock_error(sock->sk);
goto failed;
}
/* socket del cliente ready */
}
ENABLE_EVENTS();
return (mlink);
failed:
ENABLE_EVENTS();
if (sock)
sock_release(sock);
if (mlink)
kfree(mlink);
return (0);
}
mosix_link *comm_close()
Esta función cierra el socket abierto para una comunicacion establecida con anterioridad.
void
comm_close(mosix_link *mlink)
{
unsigned int ours = 0;
if (!mlink) { /* si la funcion se llama con NULL */
ours = 1;
mlink = current->mosix.contact;
}
comm_shutdown(mlink); /* termina la comunicacion con este canal */
sock_release(mlink->sock);
if (ours)
current->mosix.contact = NULL;
/* apunta el contacto del proceso en curso a NULL */
kfree(mlink); /*libera la capa de enlace */
}
static int config_shutdown(void)
Cuando se indica a linux que el nodo debe apagarse, openmosix deberá
finalizar el servicio. Apagar un nodo de modo ilegal puede conllevar la
pérdida irreparable de los procesos que en él hubieran migrado.
static int
config_shutdown(void)
{
struct mosixnet *svmton;
int svnmton, svpe, svnpe, svmaxpe;
int error;
struct task_struct *t1, *t2;
/* temporarily change configuration */
lock_mosix();
svpe = PE;
svnpe = NPE;
svmaxpe = MAXPE;
svmton = mosnet;
svnmton = nmosnet;
mosnet = NULL;
nmosnet = 0;
NPE = MAXPE = 0;
unlock_mosix();
/* retornamos los procesos migrados y expedimos los ajenos */
if ((error = config_validate()))
goto fail;
lock_mosix();
PE = 0;
unlock_mosix();
info_reconfig();
/* detenemos los daemons */
lock_mosix();
if((t1 = info_proc))
get_task_struct(t1);
if((t2 = mig_proc))
get_task_struct(t2);
unlock_mosix();
if(t1)
{
send_sig(SIGALRM, t1, 1);
free_task_struct(t1);
}
if(t2)
{
send_sig(SIGALRM, t2, 1);
free_task_struct(t2);
}
lock_mosix();
while ((mig_daemon_active || info_daemon_active) &&
!signal_pending(current))
{
unlock_mosix();
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(HZ/10);
lock_mosix();
}
unlock_mosix();
set_current_state(TASK_RUNNING);
if (signal_pending(current))
{
error = -ERESTART;
goto fail;
}
printk(KERN_NOTICE "openMosix configuration disabled\n");
unregister_reboot_notifier(&mosix_notifier);
if (svnmton) {
kfree(svmton);
kfree(mosnetstat);
}
lock_mosix();
pe_ready = 0;
unlock_mosix();
#ifdef CONFIG_MOSIX_FS
mfs_change_pe();
#endif /* CONFIG_MOSIX_FS */
return (0);
fail:
lock_mosix();
PE = svpe;
NPE = svnpe;
MAXPE = svmaxpe;
mosnet = svmton;
nmosnet = svnmton;
unlock_mosix();
wake_up(&wait_for_mosix_config);
return (error);
}
Véase como se calcula la carga de un nodo en función de la ocupación de sus recursos.
void mosix_calc_load(unsigned long unused)
void
mosix_calc_load(unsigned long unused)
{
struct task_struct *p;
register struct mosix_task *m;
register int ladd, cpu, ticks;
unsigned long flags;
unsigned long newload;
#ifdef CONFIG_MOSIX_LOADLIMIT
#if 0
static int ii=0, iii=0;
#endif
unsigned long loadremote, loadlocal, cpulocal, cpuremote;
int ii;
#endif
int new_expload;
unsigned new_cpuse;
unsigned new_came;
static unsigned upper_load; /* load estimado */
static unsigned accload; /* load acumulado */
static int display_counter = 0;
#ifdef CONFIG_MOSIX_RESEARCH
unsigned int new_io_read;
unsigned int new_io_write;
unsigned int major;
unsigned int disk;
#endif /* CONFIG_MOSIX_RESEARCH */
ticks = load_ticks;
cpu = cpuse;
ladd = load_adder;
cpuse = load_adder = load_ticks = 0;
ladd = ladd * ((long long)(MF * STD_SPD)) /
(ticks * cpuspeed * smp_num_cpus);
if(ladd * 128 > accload) /* poco aumento de carga */
accload = accload * DECAY + ladd * 128 * NEWDATA;
else /* rapido descenso de carga */
accload = ladd * 128;
if(ladd >= upper_load) /* rapido aumento de carga */
upper_load = ladd;
else /* very slowly down */
upper_load = (upper_load * 7 + ladd) / 8;
new_cpuse = (acpuse * 3 + cpu * MF / ticks + 3) / 4;
newload = (accload+64) / 128;
new_expload = (upper_load + stable_export +
came_lately4 * MF * STD_SPD /
(4 * cpuspeed * smp_num_cpus)) *
MF * smp_num_cpus / new_cpuse;
if(newload < load_left)
newload = 0;
else
newload -= load_left;
newload = newload * MF * smp_num_cpus / new_cpuse;
new_came = came_lately4 * DECAY + coming_in * 4 * NEWDATA;
spin_lock_irqsave(&runqueue_lock, flags);
#ifdef CONFIG_MOSIX_LOADLIMIT
loadlocal = loadremote = cpulocal = cpuremote = 0;
#if 0
ii = (ii+1) & 0xf;
#endif
#endif
for_each_task(p)
{
m = &p->mosix;
if(m->runstart)
{
m->ran += ticks + 1 - m->runstart;
m->runstart = 1;
}
m->load = m->load * DECAY + m->ran * MF * 4*NEWDATA/ticks;
#ifdef CONFIG_MOSIX_LOADLIMIT
if (m->dflags & DREMOTE)
{
if (m->last_per_cpu_utime[0])
{
/* this means that at least one time we were already here */
for (ii = 0; ii < smp_num_cpus; ii++)
{
cpuremote += p->per_cpu_utime[ii] -
m->last_per_cpu_utime[ii];
cpuremote += p->per_cpu_stime[ii] -
m->last_per_cpu_stime[ii];
}
}
loadremote += m->load;
}
else
{
if (m->last_per_cpu_utime[0])
{
for (ii = 0 ; ii < smp_num_cpus; ii++)
{
cpulocal += p->per_cpu_utime[ii] -
m->last_per_cpu_utime[ii];
cpulocal += p->per_cpu_stime[ii] -
m->last_per_cpu_stime[ii];
}
}
loadlocal += m->load;
}
for (ii = 0; ii < smp_num_cpus; ii++)
{
m->last_per_cpu_utime[ii] = p->per_cpu_utime[ii];
m->last_per_cpu_stime[ii] = p->per_cpu_stime[ii];
}
#if 0
if (!ii)
printk("PID: %d m->load: %d m->ran: %d ticks: %d ranstart:%d MF:%d\n",
p->pid, m->load, m->ran, ticks, m->runstart, MF);
#endif
#endif
m->ran = 0;
m->page_allocs >>= 1; /* decay in time */
}
spin_unlock_irqrestore(&runqueue_lock, flags);
if(Tvis)
printk("\0337\033[22;55HL=%d,E=%d,R=%d,U=%d \0338",
(int)newload, new_expload, mosix_running,
new_cpuse);
if(Tload) {
if (!(display_counter = (display_counter + 1) & 0xf))
printk("\naccload upper_load\tload_adder\tload_ticks\n");
printk("%7d\t%10d\t%10d\t%d\n",
accload, upper_load, ladd, ticks);
}
write_lock(&loadinfo_lock);
loadinfo[0].load = newload;
#ifdef CONFIG_MOSIX_LOADLIMIT
loadinfo[0].loadremote = loadremote;
loadinfo[0].loadlocal = loadlocal;
loadinfo[0].cpulocal = cpulocal*MF / ticks;
loadinfo[0].cpuremote = cpuremote*MF / ticks;
#if 0
if (!ii)
{
iii++;
printk("loadlocal: %lu loadremote: %lu load: %lu\n", loadlocal, loadremote,
newload);
}
#endif
#endif
export_load = new_expload;
acpuse = new_cpuse;
came_lately4 = new_came;
load_left = 0;
write_unlock(&loadinfo_lock);
if((p = (struct task_struct *)info_proc))
send_sig(SIGALRM, p, 1);
}
int remote_wait()
int
remote_wait(int expect, void **head, int *hlen)
{
int type, error = 0;
register struct task_struct *p = current;
struct syscall_ret_h *rp;
unsigned int has_ret_value = 0;
int ret_value = 0; /* value set only to pacify compiler */
while(1)
{
if(URGENT_REMOTE_CONDITIONS(p) &&
!(p->mosix.dflags & DSENTURGENT))
inform_deputy_of_urgent();
if((type = comm_recv(head, hlen)) < 0) /* an error */
return(type);
if(expect == DEP_USERMODE)
/* after migration from REMOTE to REMOTE, certain "replies"
* can arrive as a result from the original call.
* Fortunately, there are not too many of them:
*/
switch(type & ~USERMODE)
{
case REM_SYSCALL|REPLY:
rp = *head;
absorb_deptime(rp->deputytime);
remote_unpack_read_cache_data(rp);
has_ret_value = 1;
ret_value = rp->ret;
/* fall through */
case REM_SYSCALL_TRACE|REPLY:
if(!(type & USERMODE))
{
comm_free(*head);
*head = NULL;
continue;
}
}
if(type & USERMODE)
{
p->mosix.dflags &= ~DPSYNC;
if(expect == DEP_USERMODE)
{
if(has_ret_value)
mos_to_regs(&p->mosix)->eax = ret_value;
return(0);
}
if(type != (expect | USERMODE))
{
printk("REMOTE-%d: Unexected USERMODE while waiting for 0x%x\n",
p->pid, expect);
mosix_panic("Unexpected USERMODE");
return(-EINVAL);
}
}
if((type & ~USERMODE) == expect)
return(0);
switch(type & ~USERMODE)
{
case DEP_SYNC:
comm_free(*head);
break;
case DEP_NOTHING:
comm_free(*head);
error = comm_send(DEP_NOTHING|REPLY, NULL, 0,
NULL, 0, 0);
break;
case DEP_MMAP:
error = remote_mmap((struct mmap_parameters_h *)*head, 0);
break;
case DEP_BRK:
error = remote_brk((struct brk_parameters_h *)*head);
break;
case DEP_MUNMAP:
error = remote_munmap((struct munmap_parameters_h *)*head);
break;
case DEP_MPROTECT:
error = remote_mprotect((struct mprotect_parameters_h *)*head);
break;
case DEP_LISTHOLD:
comm_free(*head);
error = remote_report_files();
break;
case DEP_SETUPFRAME:
error = remote_setup_frame((struct setupframe_parameters_h *)*head);
break;
case DEP_NICE:
error = remote_nice((long *)*head);
break;
case DEP_INFO:
error = remote_updinfo((struct disclosure_h *)*head);
break;
case DEP_CAPS:
error = remote_caps((kernel_cap_t *)*head);
break;
case DEP_OPCOSTS:
error = remote_depcosts(*head);
break;
case DEP_RESTORESIGCONTEXT:
error = remote_restore_sigcontext((struct sigcontext **)*head);
break;
case DEP_PREQUEST:
error = remote_prequest((struct prequest_h *)*head);
break;
case DEP_COPY_FROM_USER:
error = remote_copy_from_user((struct user_copy_h *)*head);
break;
case DEP_COPY_TO_USER:
error = remote_copy_to_user((struct user_copy_h *)*head);
break;
case DEP_DATA_TO_USER:
error = remote_data_to_user((struct user_copy_h *)*head);
break;
case DEP_CLEAR_USER:
error = remote_clear_user((struct user_copy_h *)*head);
break;
case DEP_STRNCPY_FROM_USER:
error = remote_strncpy_from_user((struct user_copy_h *)*head);
break;
case DEP_STRNLEN_USER:
error = remote_strnlen_user((struct strnlen_user_h *)*head);
break;
case DEP_VERIFY_WRITE:
error = remote_verify_write((struct user_copy_h *)*head);
break;
case DEP_CSUM_COPY_FROM_USER:
error = remote_csum_copy_from_user((struct user_csum_copy_h *)*head);
break;
case DEP_CACHE_READ_DATA:
error = remote_unpack_read_cache_data(NULL);
/* NO REPLY! */
break;
case DEP_RLIMIT:
error = remote_rlimit((struct rlimit_h *)*head);
break;
case DEP_TAKEURGENT:
comm_free(*head);
error = remote_urgent();
break;
case DEP_RUSAGE:
error = remote_rusage((int *)*head);
break;
case DEP_PERSONALITY:
error = remote_personality((unsigned long *)*head);
break;
case DEP_EXECVE_COUNTS:
error = remote_execve_counts((struct execve_counts_h *)*head);
break;
case DEP_BRING_STRINGS:
error = remote_bring_strings((struct execve_bring_strings_h *)*head);
break;
case DEP_SETUP_ARGS:
error = remote_setup_args((struct execve_setup_args_h *)*head);
break;
case DEP_EXEC_MMAP:
error = remote_exec_mmap();
break;
case DEP_INIT_AOUT_MM:
error = remote_init_aout_mm((struct exec *)*head);
break;
case DEP_ELF_SETUP:
error = remote_elf_setup((struct execve_elf_setup_h *)*head);
break;
case DEP_FIX_ELF_AOUT:
error = remote_fix_elf_aout((struct execve_fix_elf_aout_h *)*head);
break;
case DEP_DUMP_THREAD:
/* comm_free(*head); is not needed (NULL) */
error = remote_dump_thread();
break;
case DEP_LIST_VMAS:
/* comm_free(*head); is not needed (NULL) */
error = remote_list_vmas();
break;
case DEP_PLEASE_FORK:
error = remote_fork((struct fork_h *)*head);
break;
case DEP_BRING_ME_REGS:
error = remote_bring_me_regs((unsigned long *)*head);
break;
case DEP_DUMP_FPU:
/* comm_free(*head); is not needed (NULL) */
error = remote_dump_fpu();
break;
case DEP_COME_BACK:
if (!remote_come_back(*head) || bootexpel)
remote_disappear();
break;
case DEP_PLEASE_MIGRATE:
error = remote_goto_remote(*head);
break;
case DEP_CONSIDER:
error = remote_consider((int *)*head);
break;
case DEP_UPDATE_DECAY:
error = remote_setdecay((struct decay_h *)*head);
break;
case DEP_UPDATE_LOCK:
error = remote_set_lock((int *)*head);
break;
case DEP_UPDATE_MIGFILTER:
error = remote_set_migfilter((int *)*head);
break;
case DEP_UPDATE_MIGPOLICY:
error = remote_set_migpolicy((int *)*head);
break;
case DEP_UPDATE_MIGNODES:
error = remote_set_mignodes((int *)*head);
break;
case DEP_PSINFO:
/* comm_free(*head); is not needed (NULL) */
error = remote_psinfo();
break;
#ifdef CONFIG_MOSIX_DFSA
case DEP_DFSA_CLEAR:
remote_clear_dfsa();
error = comm_send(DEP_DFSA_CLEAR|REPLY, NULL, 0,
NULL, 0, 0);
break;
case DEP_DFSA_CHANGES:
error = remote_receive_dfsachanges((int *)*head);
break;
case DEP_READ_YOURSELF:
error = remote_read_yourself(
(struct read_yourself_h *)*head);
break;
#endif /* CONFIG_MOSIX_DFSA */
default:
printk("openMosix: remote type %x unexpected\n", type);
if(type != MIG_REQUEST)
mosix_panic("deputy_wait");
return(-EINVAL);
}
if(error)
{
return(error);
}
}
}