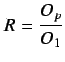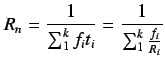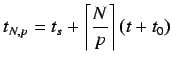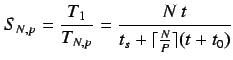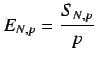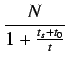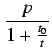Se hablará de programación paralela y los problemas que pueden surgir cuando se trata de utilizar este paradigma. Para ello debe considerarse el sistema sobre el que se programa y se lanzan los programas paralelos: ya sean multiprocesadores o, como será el caso, multicomputadores. Al explicar estos límites que impone la propia arquitectura tendrá que hablarse forzosamente de la ley de Ahmdal así como de otros problemas relativos a la ordenación de instrucciones debido a dependencias.
En general en esta sección se hablará acerca de todos los conceptos que interesan a la hora de programar aplicaciones y hacerlo utilizando de una manera u otra el paralelismo. Se darán diversos ejemplos de programación con openMosix y explicaciones con PVM o MPI y se profundizará en conceptos como la granularidad del paralelismo o el problema de la transparencia en lo que se refiere a la programación.
Acceleración (speedup ![]() ). Ratio entre el tiempo de una
ejecución serie y una paralela.
). Ratio entre el tiempo de una
ejecución serie y una paralela.
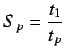 procesador,
procesador,
Eficiencia (E). Ratio entre la acceleración de una ejecución
paralela y el número de procesadores.
Redundancia (R). Ratio entre el número de operaciones realizadas
utilizando ![]() procesadores en una ejecuciópn paralela y su correspondiente
ejecución serie en 1 procesador.
procesadores en una ejecuciópn paralela y su correspondiente
ejecución serie en 1 procesador.
Utilización (U). Ratio entre 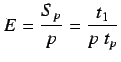 y el número de operaciones que
podrian realizarse utilizando
y el número de operaciones que
podrian realizarse utilizando ![]() procesadores en
procesadores en ![]() unidades de tiempo.
unidades de tiempo.
Sea ![]() el tiempo requerido en computar
el tiempo requerido en computar 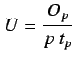 operaciones de
operaciones de ![]() tipos
diferentes, donde cada tipo de operación consiste en
tipos
diferentes, donde cada tipo de operación consiste en ![]() operaciones
simples las cuales requieren
operaciones
simples las cuales requieren ![]() segundos cada una para su
ejecución. Luego:
segundos cada una para su
ejecución. Luego:
![]() y
y
![]() . Por definición
sabemos que
. Por definición
sabemos que
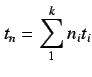 MFlops.
MFlops.
Si definimos:
luego
| (2.5) |
donde
![]() .
.
Lo importante de esta ecuación es que muestra que una sola operación
donde su ejecución no sea equiparable con el resto, en cuanto al tiempo de ejecución, tiene una
gran influencia en el rendimiento global del sistema.
II. LEY DE AMDAHL
Para comprender esta ley sería conveniente recuperar la analogía del problema que se planteaba en el primer tema, acerca de la persona que debía colocar los libros en dos partes. En el caso de la ordenación de la biblioteca se llegaba a la conclusión de que era estúpido contratar a 200 personas para que organizasen una biblioteca de 200 ejemplares, por la falta de eficiencia en las operaciones.
El speedup -o mejora de rendimiento - idealmente aumenta linealmente con el número de unidades de procesamiento que posea el sistema. Esto es en un principio cierto, pero estamos contando en todo momento con un programa modelo ideal, sin tener en cuenta la naturaleza de dicho programa. En el caso de programas concretos hemos de contar con la naturaleza del programa, qué pretende solucionar y la manera en la que lo soluciona. Eso permitirá poder dar con la medida real del speedup.
En cualquier programa paralelizado existen dos tipos de código: el código paralelizado y el código secuencial. Como es sabido existen ciertas secciones de código que ya sea por dependencias, por acceso a recursos únicos o por requerimientos del problema no pueden ser paralelizadas. Estas secciones conforman el código secuencial, que debe ser ejecutado por un solo elemento procesador. Es pues lógico afirmar que la mejora de rendimiento de un programa dependerá completamente de:
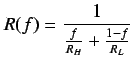 .
).
.
).
Esta es la llamada ley de Amdahl y fue descrita por Gene Amdahl
en 1967.
Las implicaciones que trae esta ecuación son, a pesar de que no
tenga en cuenta las características de cada sistema en concreto:
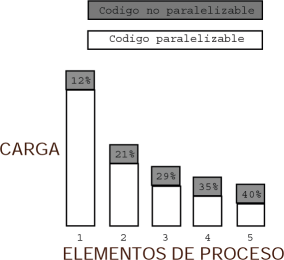
Supongamos ahora que tenemos un programa que inicialmente no hemos paralelizado, cuyos tiempos de ejecución son 12% y 88%, en serie y en paralelo respectivamente.
Como se puede ver en la figura, la parte no paralelizable del código impide que se pueda escalar de forma lineal, llegará un momento que añadir nuevos procesadores no añadirá una ventaja real al sistema, porque todo lo que estará en ejecución será código secuencial. Por lo tanto para maximizar el aprovechamiento de los sistemas paralelos debe tenerse mucho cuidado con la forma de paralelizar las aplicaciones: cuanto más código secuencial tengan, más problemas de escalabilidad.
La ley de Amdahl es un caso particular del Principio Armónico Ponderado,
anteriormente descrito. Si recuperamos:
![]() y hacemos
y hacemos ![]() queda
queda
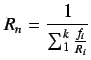
si se igualan
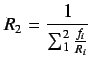 : fracción serie
: fracción serie
da la forma de la Ec.(![[*]](crossref.png) )
)
![]()
![]() .
.
III. LíMITES DE LA COMPUTACIÓN PARALELA
Un programa paralelo requiere sincronizar las tareas de que se
compone. Estas tareas se distribuyen entre los diferentes procesadores del
sistema paralelo. La suma de los tiempo de ejecución de estas tareas en un
sistema paralelo es más grande que la suma de los tiempos de ejecución en
un solo proesador. Esto es debido a diferentes tiempos adicionales de
procesamiento (overhead).
Sean:
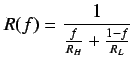 : granularidad de la tarea. valor medio del tiempo de
ejecución de las diferentes tareas.
: granularidad de la tarea. valor medio del tiempo de
ejecución de las diferentes tareas.
El tiempo requerido para ejecutar ![]() tareas, cadauna con un tiempo de
ejecución en un solo procesador viene dado por
tareas, cadauna con un tiempo de
ejecución en un solo procesador viene dado por
En un entorno paralelo cada tarea requiere ![]() unidades de tiempo para su
ejecución. El tiempo requerido para ejecutar
unidades de tiempo para su
ejecución. El tiempo requerido para ejecutar ![]() tareas en
tareas en ![]() procesadores
será pues:
procesadores
será pues:
y recuperando el speedup, esta vez siendo el cómputo las ![]() tareas
tareas
y la eficiencia ahora quedaria determinada como
Los límites de la computación paralela estan reflejados en el cuadro .
Para lograrlo deben solucionar de la manera más apropiada posible retardos por dependencias2.7. Generalmente esto se soluciona con renombramiento de registros (fase que puede o no hacer el compilador), lanzamiento de instrucciones fuera de orden, unidades superescalares y supervectoriales y algunas otras técnicas que se describirán sin ahondar en el capítulo dedicado a arquitecturas.
La granularidad del hardware es la instrucción máquina (o en lenguaje ensamblador). Esta unidad es la más fina que puede tratar. Existen gran variedad de mejoras de rendimiento a los límites que se imponen por el programa, estas mejoras se van incorporando en los procesadores de última generación. El problema es que esta solución puede resultar en muchos casos demasiado cara, sobretodo por la dificultad o tiempos de implementación. Además siempre se necesita cierta ayuda de parte del software, principalmente el compilador. Así aunque el Pentium4 tenga nuevas instrucciones vectoriales SSEII, no son prácticamente usadas por los compiladores actuales y el rendimiento de un P4 es bastante inferior al esperado. En cambio usando el compilador especialmente desarrollado por Intel, los mismos programas aprovechan las instrucciones vectoriales del procesador mucho mejor con lo que se consiguen programas mucho más rápidos.
Hoy en día es difícil ver programar en ensamblador para procesadores que no estén dedicados a tareas como dispositivos empotrados o de tiempo real, e incluso en estos este lenguaje se hace más raro cada dia. Por lo tanto las optimizaciones de uso de las nuevas capacidades de los procesadores tienen que venir de parte del compilador que es quien se encarga de trabajar a nivel más bajo que el programador.
Así pues a las fases de análisis, diseño e implementación hay que añadir una fase de paralelización, en la que se deberá tener en cuenta las necesidades del programa y del problema a resolver, así como de los medios de los que se disponen para poder hacer que el programa aumente el rendimiento a medida que aumenta la capacidad de procesamiento de sistema.
Existen otras muchas limitaciones además de la ley de Amdahl que afectan al desarrollo de aplicaciones paralelas, comenzando por el sistema elegido para paralelizar aplicaciones, hasta la granularidad del paralelismo (que a este nivel siempre será denominado paralelismo de grano grueso). Muchos de estos métodos son brevemente referenciados en el tema de sistemas distribuidos, otros son de una granularidad algo más fina, relativos a compiladores que preparán el código paralelizado para sistemas especiales.
Para ilustrar esto con un caso pueden suponerse dos compiladores diferentes para un mismo lenguaje.
Un compilador inteligente frente a uno que no lo
es tanto ante una misma entrada: un programa con una secuencia de
divisiones con coma flotante, después unas sumas del mismo tipo y por último
unas operaciones con enteros, todas sin dependencias entre
sí![]() curre que:
curre que:
Una vez vistos los tipos de granularidades existentes podemos catalogar algunos de los sistemas que vamos a tratar a lo largo de este documento. Para empezar cabe señalar que mayormente se tratará del estudio de sistemas distribuidos y clusters, esto implica que el sistema está compuesto por diversas máquinas con un sistema operativo que puede hacer el sistema más acoplado o no. El software de cluster en el que se particulariza es openMosix, como se explicará con mucho más detalle. La granularidad de openMosix está en los procesos, es decir, podemos paralelizar procesos y hacer que estos se ejecuten en nodos distintos. De hecho openMosix se encarga de balancear la carga de los nodos de modo que la carga global del sistema permanezca homogéneamente distribuida. Este tipo de granularidad es del tipo medio, si bien puede ser confundida con la de grano grueso (el límite siempre esta bastante difuso). Otros sistemas como pueden ser RPC, MPI, PVM o clusters Beowulf se acercan más al paralelismo de grano grueso.
En el que se requiere una biblioteca de funciones especiales que se encargan tanto de realizar la comunicación como los métodos de migración y demás factores que en un principio2.8 no debe afectar al programador, el cual debe abstraerse de esta capa. Este tipo de modelo es el que utiliza RPC, MPI o PVM. Requiere un conocimiento especial de dichas bibliotecas, lo que limita la velocidad de desarrollo del software y además lo hace más costoso debido al tiempo que se debe gastar en el conocimiento de las funciones.
Es un modelo quizá más atractivo. Basa todo su funcionamiento en que el programador sepa lo mínimo del sistema para paralelizar sus procesos. Generalmente este modelo lo explotan los compiladores especiales de un sistema particular.
Por otro lado se suele depender de macros o funciones especiales que delimitan la granularidad de los procesos a migrar. Un caso especial de este tipo es openMosix: la programación y migración de procesos en openMosix no requiere de conocimiento del usuario respecto al cluster de máquinas. Lo ideal para obtener transparencia en la programación será programar de manera completamente implícita y que al mismo tiempo el sistema implantado fuese lo menos intrusivo posible en lo que se refiere a comportamiento con el usuario final.
Para que un sistema fuese realmente transparente y al mismo tiempo suficientemente eficiente, en lo que se refiere a programación paralela, el programador debería conocer a fondo la programación del sistema, i.e. las habituales llamadas de creación de memoria, librerías estándar, o basadas en las estándar, llamadas a sistema y demás herramientas habituales de la programación. Por otro lado, el compilador o el sistema se deberían encargar de efectuar todas aquellas tareas que de manera habitual se hacen en los sistemas que actualmente existen, es decir, la comunicación entre procesos, la localización de dichos procesos, rutinas o tareas, la paralelización del código del programa y demás tareas. Así el programador no tendría que preocuparse de los detalles y se podrían hacer desarrollos más rápidos y baratos.
Lamentablemente dicho sistema no existe. La explotación de los sistemas distribuidos de momento requiere un gran conocimiento del sistema en el que se trabaja por parte del programador. De hecho, las optimizaciones de los algoritmos se basan en gran medida no en cómo de bueno es el modelo del algoritmo, sino en las capacidades especiales de cada sistema.
Es decir, cada sistema especial como puede ser Beowulf, PVM u openMosix tienen puntos fuertes y puntos débiles en lo que se refiere a la programación, y es mediante el conocimiento de estas características de la manera que se pueden optimizar programas paralelos. Un ejemplo de esto puede encontrarse en aplicaciones que requieren comunicación entre procesos. El caso de openMosix, como se verá más detalladamente, es el caso de uno de los sistemas que poco a poco ha pretendido ser un sistema lo mas transparente posible y que basa toda su granularidad del paralelismo en el proceso. Las aplicaciones diseñadas para ejecutarse en openMosix contienen procesos que se ejecutan de manera independiente y que de una manera u otra se deben comunicar de manera transparente con otros procesos. Estos procesos pueden estar en el nodo local donde se ejecutaron o en otros nodos, lo cual complica la cosa, ya que la relación que une a un proceso con otro puede ser un pipe con nombre y sin embargo estar los procesos en dos nodos distintos.
Imagínese el típico caso de la multiplicación de una matriz. Se supone que el caso ideal para openMosix sería utilizar memoria compartida para las matrices y dejar que el sistema haga todo de la manera más efectiva posible. Sin embargo openMosix no implementa en las versiones actuales2.9 un manejo eficiente de la memoria compartida y por tanto se deben buscar otros mecanismos de programación para aprovechar al máximo la utilización del sistema.
Otro posible ejemplo sería el de PVM. Supóngase el caso de determinadas tareas con uso de CPU intensiva que se sitúan en unos nodos concretos antes de empezar su ejecución. Supóngase también que el tiempo de ejecución de dichas tareas es en muchos casos aleatorio, y por tanto, el sistema tendrá muchos nodos altamente cargados y otros poco cargados. Como PVM no posee de la capacidad de balanceo automático de carga que tiene openMosix se estará desaprovechando la capacidad de cómputo del cluster en general y la tarea que se le encomendó tendrá que esperar hasta que el último de los nodos acabe con ella, mientras los demás nodos están ociosos y no pueden ayudar en su finalización. En cualquier caso la transparencia en los sistemas distribuidos y clusters que más se utilizan actualmente requiere de un conocimiento exhaustivo por parte del programador, lo que en muchos casos requiere un coste adicional2.10.
Por otro lado está el problema de la intrusión en el código. En este caso se supondrá el caso ideal de haber conseguido un sistema realmente transparente a los ojos del programador, lo que implicaría que la mayoría de las aplicaciones necesitarían de una compilación especial o un compilador especial para el sistema en concreto, lo que hará las aplicaciones normales incompatibles con nuestro sistema, teniendo que compilar todas las aplicaciones de nuevo. En un principio se podría pensar que en el caso de el sistema operativo linux esto no sería problema más que para las distribuciones (aparte de algún programa de más bajo nivel que habría que rehacer).
El problema real está en lo intrusivo que puede llegar a ser un sistema de estas características, cuando los servicios distribuidos que se proveerían solamente serían apreciados por una pequeña parte de los usuarios del sistema operativo, seguramente por esto se crearía más antipatía que simpatía a estos cambios en el kernel.
Uno de estos casos ha sido el de Amnon Barak. Amnon Barak es el líder del proyecto Mosix. En una de las primeras implementaciones trató de hacer un sistema como el que se ha descrito, con el resultado de tener que implementar aproximadamente el 60% del kernel, más la reimplementación de las librerías necesarias para ejecutar los programas más habituales; esto sin tener en cuenta que todos los programas que eran afectados por dichas librerías debían de ser recompilados para poder ser utilizados. De esta manera se puede hacer notar que por el momento el tener un sistema transparente en lo que se refiere a la programación supone tener un sistema altamente intrusivo.
El primer paso en el desarrollo de un programa paralelizado es, como siempre, plantear el problema mediante técnicas de divide y vencerás. Deberá localizarse lo paralelizable en el problema de manera abstracta antes de pensar en la paralelización del código, es decir que existen problemas inherentemente paralelos, como pueden ser la suma de las componentes de dos vectores según sus posiciones o la renderización de imágenes. Estos problemas se pueden resolver de manera óptima. Por otro lado, están los problemas en los que en un principio no vemos claramente la inherencia del paralelismo como pueden ser la multiplicación de matrices, compresión de la información o compilación.
Teóricamente se puede paralelizar cualquier cosa que se haya diseminado mediante técnicas de divide y vencerás, procesos, módulos rutinas, o algoritmos paralelos completamente.
Existen dos formas bien conocidas y fáciles de comprender de paralelismo:
Aquí se sigue la misma idea pero a nivel de software, se dividen los procesos formando una cadena y dependiendo uno del siguiente. Aunque al principio no se logre el paralelismo, una vez que se ponen todos los nodos a trabajar (i.e. cuando hayamos ejecutado N veces lo que estemos ejecutando, siendo N el número de pasos en los que hemos dividido la aplicación) se consiguen que todos los nodos estén trabajando a la vez si todas las funciones tardan el mismo tiempo en completarse. Sino, las demás funciones tienen que esperar a que se complete la función más lenta.
La idea es exactamente la misma que trataremos en el tema Arquitecturas aunque allí se referencie con el término pipeline. Esta forma de paralelizar no es ampliamente usada puesto que es muy difícil dividir en funciones que tarden el mismo tiempo en ejecutarse. Sólo se usa en casos concretos donde se ve claramente que es una buena opción por ser fácilmente implementable.
Ejemplos pueden ser los films Final Fantasy o El señor de los anillos que fueron renderizadas en un cluster de renderización con el software Maya y Renderman. Esta forma de renderizar se basa en dividir los frames (cuadros) que se deban renderizar en una escena en concreto o todos los frames de la película entre todos los ordenadores. Para ser más exactos, primero se divide el número de frames por el número de nodos y se envía el número resultante de frames a cada nodo (suponiendo que es un cluster donde todos los nodos tienen la misma capacidad de proceso). Esta es la fase de preparación y suele ser secuencial, puesto que es una pequeña parte de la producción. Una vez hecho esto, cada nodo renderiza los frames que le fueron asignados. Esta fase puede durar semanas. Una vez se tienen todos los frames se unen en un fichero único que tiene toda la película. En este caso en particular se usa paralelismo de datos, y aunque algunas imágenes tardan más en renderizarse que otras y por lo tanto algún nodo tardará menos en acabar su trabajo que otro, lo que se hace es no elegir imágenes de forma secuencial (de la 1 a la n al nodo 1) sino paralela (1 al nodo 1, 2 al nodo 2... n+1 al nodo n+1) esto suele compensar la carga entre los nodos por lo que más o menos todos los nodos se mantienen en el máximo rendimiento (si no se comprende esto, piense en lo poco que tardaría el nodo que renderize unos títulos de crédito simples).
Una vez analizada la fuente de paralelismo de los programas sólo falta comenzar a realizar el estudio en pseudocódigo o cualquier otro sistema parecido. Hay que conocer los límites y características del sistema para el que va a programarse. La migración o ubicación de un proceso, módulo o rutina está ligada a un coste adicional; hemos de conocer los costes de nuestros sistemas y evaluar la conveniencia de paralelizar acciones.
Un programa paralelizado no debe obtener peor tasa de eficiencia que un programa secuencial, lo cual no siempre se cumple ni es posible debido a transferencias de comunicación entre los procesos, módulos, nodos o elementos del cluster. En este apartado juega un papel importante la red de comunicación, el cual ocupa un capítulo entero. La paralelización del código está comprometida a las ventajas de los sistemas implantados, por tanto no podremos hablar en forma general de ésta. En cualquier caso se dará una visión de un sistema concreto openMosix y se hará alguna alusión a sistemas del tipo PVM.
La paralelización del software se basa en principios generales asociados a la manera de programar que utilizamos actualmente tanto por arquitectura de los computadores, funcionamiento de compiladores como lenguajes de programac ión. Uno de estos principios generales es el denominado principio de localidad, del cual existen dos tipos de localidades en nuestros programas:
Este tipo de localización se basa en la manera en la que se puede encontrar el código de los programas y como se ejecutan estos en el tiempo. Generalmente, los programas están compuestos por un alto porcentaje de estructuras en forma de bucle que ejecutan instrucciones. Lo que implica que con tener en memoria estos bucles, tendremos acceso a la mayor parte del programa. Por otro lado normalmente procedimientos o funciones que están relacionadas suelen estar en zonas de memoria adyacentes, así como las instrucciones que se ejecutan secuencialmente.
Este tipo de localización se basa en la manera en la que los programadores organizamos nuestros datos en estructuras, objetos, matrices, vectores. Esta manera de organizar elementos de los programas que están muy relacionados entre sí hace que a la hora de solicitar memoria para los mismos éstos sean alojados en segmentos contiguos de memoria. Cuando en un programa se pide memoria, se intenta pedir de una vez toda la memoria que vayan a usar la mayor parte de datos posible, para precisamente tener que estar pidiendo memoria continuamente. Esto produce esta localidad.
Nuestra intención principal debería ser explotar el paralelismo al máximo nivel, para esto pueden utilizarse las típicas formas que se usan para organizar la información y paralelizar al máximo posible, accesos a la misma, operaciones a realizar y demás acciones. Por ejemplo, un programa cuyo núcleo de proceso principal se encuentre en un bucle sería perfectamente paralelizable, pongamos que el bucle se realizara 15000 veces. En el caso de tener 3 nodos podemos distribuir su ejecución en 3 procedimientos que se ejecuten en estos tres nodos y que realicen bucles de 5000 iteraciones de bucle cada uno. Para que esto sea posible es necesario cumplir un objetivo que también debemos tener en cuenta siempre que programemos aplicaciones paralelas en sistemas distribuidos como clusters. Los segmentos de código, rutinas, bucles o cualquier operación sobre estructura s de datos, deben ser ortogonales, en el sentido de que no deben interferir entre sí.
Al paralelizar programas se ve que se obtiene como ventaja un incremento del rendimiento. Este incremento puede ser decremento si estamos comunicando continuamente nuestros procesos a través de una red, que generalmente suele ser el cuello de botella del sistema. Es por esto que los elementos de procesos a paralelizar deben ser lo más independientes y ortogonales posibles.
También hay que pensar que si un proceso tiene que dedicar instrucciones a la comunicación con otros procesos, este código no es paralelizable y además es código que añadimos a cada uno de los procesos, por lo que la escalabilidad disminuye drásticamente con la cantidad de información pasada entre procesos. Aquí es cuando es especialmente importante el desarrollo software pues una buena división en procesos puede evitar esta sobrecarga de comunicación.
En el caso que aquí se trata, programación de clusters o sistemas distribuidos, se llamarán elementos de proceso a los módulos, procesos, procedimientos o rutinas que se consolidan como unidades de proceso a ejecutar en los nodos, aunque haya que diferenciarlos claramente del concepto que tiene el término elemento de proceso en sistemas multiprocesad or.
Los elementos de proceso deben ser ortogonales entre sí. El problema que anula generalmente la ortogonalidad de estos elementos, esto es la dependencia de datos. Cuando surgen dependencias, ya sea de datos o de control2.11, el programa o sistema deja de ser paralelizable y pasa a ser secuencial, se necesita interconectar generalmente los elementos para obtener sus resultados o para obtener sus estados y poder continuar el programa, esto requiere como ya hemos dicho comunicación a través de la red, lo que puede llegar a ser bastante costoso.
No existe un método general para evitar las dependencias o para ortogonalizar elementos de proceso, es por esta razón por la que todavía puede ser denominado arte en lugar de ciencia a este tipo de investigaciones. En la mayoría de ocasiones se debe utilizar algoritmos que en programación normal se darían por descartados a simple vista. En otras ocasiones el sistema permite utilizar algoritmos óptimos paralelizables. De este modo, aunque el sistema sea el mejor sistema paralelo existente, si la resolución de los problemas que tienen que hacer no son paralelizables estaremos tirando tiempo y dinero. La mayoría del esfuerzo en el desarrollo de programas que resuelvan problemas de manera paralela, se gasta en:
En el cual se evalúe las maneras de atacar el problema, se dividan las distintas secciones de éste y se tenga en cuenta las implicaciones. Se corresponde con la parte de análisis del programa
En la cual se busca la ortogonalización del problema para que este pueda ser fácilmente paralelizable. Se evalúan todas las posibles vías de paralelización y se eligen las que más se adecuen al sistema concreto sobre el que se vaya a ejecutar.
Tanto a nivel práctico como teórico.
Por ejemplo en el caso de PVM basta con conocer el modelo de programación,
su sintaxis y el cluster sobre el que se va a ejecutar, la carga que puede
aceptar cada nodo, dispositivos y recursos de cada nodo, etc.
En el caso de openMosix se debe conocer el estado del cluster, las maneras
actuales de poder comunicar procesos en el sistema, creación de entorno
adecuado.
Cada sistema debe ser explotado de una manera diferente.
Este apartado depende completamente de los dos anteriores, es decir, sólo se puede hacer correctamente en el caso que se hayan cumplido los dos apartados anteriores, corresponde con la fase de diseño del programa. Es en esta parte del desarrollo en la que muchas veces se deben cambiar algoritmos adecuados por otros que lo son menos para que sean más fácilmente paralelizables en un sistema concreto y se obtenga mejor rendimiento del mismo.
Muchos programas desarrollados mediante el paradigma de programación paralela hacen uso de un modelo de programación poco ortodoxa, que los hace difíciles de probar y de depurar al mismo tiempo. Por ejemplo, cuando se ejecuta el gdb sobre un programa que lanza otros programas y se comunica con estos mismos, la depuración se hace un tanto más difícil. Otra consecuencia de la programación poco ortodoxa es que en muchas ocasiones el programa no se comporta de la manera o con la eficiencia con la que habíamos supuesto contaría en un principio2.12.
En el campo científico es en el que más se están haciendo desarrollos de este tipo de programas ya que es el campo en el que generalmente es más fácil encontrarse problemas a paralelizar por la naturaleza de estos. Actualmente otras nuevas vías de desarrollo están siendo bastante utilizadas.
Existen programas de renderizado como MAYA o 3D Studio que utilizan paralelismo en forma de threads para poder hacer uso de sistemas multiprocesador, de modo que el tiempo de renderizado se reduzca considerablemente. Es una lástima que ninguno de estos sistemas haga uso de soluciones libres que permitan abaratar el coste del sistema, por ejemplo un MAYA para Linux (que existe) que utilice un cluster Beowulf, PVM, MPI u openMosix permitiendo abaratar gastos a la empresa que lo utiliza y al mismo tiempo, reducir tiempos de renderizado. Para aprovechar varios nodos se usa un programa especial llamado Renderman el cual decide a que nodo enviar las imágenes a ser renderizadas. Este programa es una solución particular que se desarrolló para Toy Story (cluster de máquinas SUN) y que sólo funciona para el problema de las granjas de renderización.
Existen también múltiples entornos de trabajo distribuidos en empresas que utilizan de una manera muy superficial paralelización de los problemas, ya que la mayoría están dominados por paradigma cliente-servidor que impera en el mercado.
En el campo científico es ampliamente utilizado. Un ejemplo real es el de estudio oceanográfico realizado por el instituto nacional de oceanografía española2.13, en este estudio, se utilizaban matrices descomunales para poder controlar el movimiento de las partículas comprendidas en una región de líquido, que tenía en cuenta viscosidad, temperatura, presión, viento en la capa superficial del liquido, y otras muchas variables. Este ejemplo es el típico en el cual PVM y openMosix podrían ser utilizados conjuntamente.
El ejemplo de código paralelizable más típico y simple es la multiplicación de una matriz.